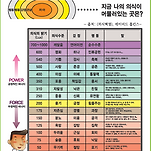
<p><span style="font-size: 11pt;">beyond reason</span><br></p><p><span style="font-size: 11pt;"><br></span></p><p><span style="font-size: 11pt;">단백질, 펩타이드, 아미노산, 각종 효소, 보조효소, DNA는 모두 단백질(C, H, O, N)</span></p><p><span style="font-size: 11pt;">아미노기(NH3), 카르복실기(COOH)와 관련되어 있음.&nbsp;</span></p><p><span style="font-size: 11pt;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">20여개의 아미노산이 50여개 모여 폴리펩티드를 만들고&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;">폴리펩티드가 수소결합, 이온결합, 공유결합, 반데발스 힘 등으로&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;">1, 2, 3, 4차 단백질 구조를 만듬.</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">'이러한 구조는 기능을 결정한다'</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">기능을 결정하는 구조를 정상적으로 복구하는 것이 치료다</span></p><p><span style="font-size: 15px; line-height: 23px;">무엇이 구조를 정상적으로 복구할 수 있을까?&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">1) 기쁨, 감사, 축복 540 이상의 의식수준</span></p><p><span style="font-size: 15px; line-height: 23px;">2) 오오라, 차크라, 기 에너지</span></p><p><span style="font-size: 15px; line-height: 23px;">3) 비타민, 미네랄, 치료적 보충제 등 미량원소</span></p><p><span style="font-size: 15px; line-height: 23px;">4) 음식에너지(ketone body)</span></p><p><span style="font-size: 15px; line-height: 23px;">5) 올바른 움직임</span></p><p><span style="font-size: 11pt;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질에 대한 기초 영양학</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"></p><p><span style="font-size: 15px; line-height: 23px;"><b>Chapter 5단백질</b><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>1. 단백질의 일반적 특성</b></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질은 신체의 기본적 구성성분, 생명의 기본물질, 중요한 영량영양소임.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;">protein이라는 말은 '으뜸가는 것 <b><span style="color: rgb(0, 85, 255);">to take the first place</span></b>'라는 그리스어에서 유래됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>1) 단백질과 질소 동화작용</b></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질은 여러가지 아미노산이 결합하여 합성됨.<b><span style="color: rgb(255, 0, 0);"> 사람은 20여가지 아미노산이 필요</span></b>함. <b><span style="color: rgb(255, 0, 0);">식물은 공기중의 이산화탄소, 물, 암모니아, 질산염, 황산염을 이용하여 단백질을 합성</span></b>하는데 이를 '<b><span style="color: rgb(9, 0, 255);">질소 동화작용'</span></b>이라고함. 사람은 식물처럼 질소 동화작용을 할 수 없기 때문에 섭취해야 함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>2) 단백질의 원소조성</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">단백질은 C, H, O, N으로 구성되어 있으며 황, 철, 인을 함유한 것도 있음.</span></b> 단백질의 종류에 따라서 질소, 수소, 산소, 탄소의 함량이 다름. 대개 <b><span style="color: rgb(9, 0, 255);">탄소 51~55%, 산소 20~23%, 질소 15.5~18.7%, 수소 6~7%, 황 0.4~1.73%</span></b>임.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/996D67375E4DB44612" class="txc-image" actualwidth="534" hspace="1" vspace="1" border="0" width="534" exif="{}" data-filename="스크린샷 2020-02-20 오전 7.18.14.png" style="clear:none;float:none;" id="A_996D67375E4DB44612FFD3"/></p><p><span style="font-size: 15px; line-height: 23px;"><b>질소계수</b><br></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질의 질소계수는 평균 16%임. 단백질을 분해하여 얻는 질소량에 6.25의 질소계수를 곱하면 단백질양을 산정할 수 있음.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>3) 단백질의 화학적 특성</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질은 아미노산이 결합된 분자량이 큰 물질임. <b><span style="color: rgb(0, 85, 255);">일상 식품에는 22가지 아미노산이 발견</span></b>되며 수십, 수백개의 아미노산이 결합되어 단백질이 합성됨. 단백질을 구성하는 기본단위인 <b><span style="color: rgb(255, 0, 0);">아미노산은 '아미노기 &nbsp;NH2와 카르복실기 COOH를 가지고 있는 화합물</span></b>임.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 아미노기(amino group)</b> - 염기성, 유기화합물이 가지는 작용기의 하나. <b><span style="color: rgb(255, 0, 0);">질소원자에 수소가 결합된 형태(-NH2)</span></b>. 양전하와 결합하여 양전하를 띠는 양이온이 될 수 있고 질소원자가 가지고 있는 비공유 전자쌍 때문에 친핵체로 작용할 수 있음.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 카르복실기(carboxyl group)</b> - 산성, 탄소, 수소, 산소로 이루어진 작용기의 하나로 -COOH &nbsp;또는 -CO2H로 표시됨. <b><span style="color: rgb(9, 0, 255);">카르복실기 구조는 중심의 탄소원자에 하나의 산소원자가 이중결합으로 연결되어 있고 하나의 하이드록시기가 단일결합으로 연결</span></b>되어 있음.&nbsp;</span><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">카복시기는 중심 탄소 원자에 하나의&nbsp;</span><a href="https://ko.wikipedia.org/w/index.php?title=%EC%B5%9C%EC%99%B8%EA%B0%81_%EC%A0%84%EC%9E%90&amp;action=edit&amp;redlink=1" class="new" title="최외각 전자 (없는 문서)" style="color: rgb(165, 88, 88); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">최외각 전자</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">를 지니고 있기 때문에, 보다 큰 분자와 결합할 수 있다. 하지만, 기본적으로 3 개의 결합을 필요로 하는 카복시기는&nbsp;</span><a href="https://ko.wikipedia.org/w/index.php?title=%ED%83%84%EC%86%8C_%EC%82%AC%EC%8A%AC&amp;action=edit&amp;redlink=1" class="new" title="탄소 사슬 (없는 문서)" style="color: rgb(165, 88, 88); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">탄소 사슬</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">의 끝부분에만 위치할 수 있다. 카복시기는&nbsp;</span><a href="https://ko.wikipedia.org/wiki/%EC%95%84%EC%84%B8%ED%8A%B8%EC%82%B0" title="아세트산" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">아세트산</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">이 수소 이온을 방출해서&nbsp;</span><a href="https://ko.wikipedia.org/wiki/%EC%95%84%EC%84%B8%ED%85%8C%EC%9D%B4%ED%8A%B8" title="아세테이트" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">아세테이트</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">가 되는 것처럼&nbsp;</span><a href="https://ko.wikipedia.org/wiki/%EC%88%98%EC%86%8C_%EC%9D%B4%EC%98%A8" title="수소 이온" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">수소 이온</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">(H+)을 내놓아&nbsp;</span><a href="https://ko.wikipedia.org/wiki/%EC%82%B0_(%ED%99%94%ED%95%99)" title="산 (화학)" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">산</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">으로 작용할 수 있다.</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/9964554C5E4DB5D614" class="txc-image" actualwidth="366" hspace="1" vspace="1" border="0" width="366" exif="{}" data-filename="스크린샷 2020-02-20 오전 7.25.01.png" style="clear:none;float:none;" id="A_9964554C5E4DB5D614DAC4"/></p><p><a href="https://ko.wikipedia.org/wiki/%EC%95%84%EB%AF%B8%EB%85%B8%EA%B8%B0" title="아미노기" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">아미노기</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">와&nbsp;</span><a href="https://ko.wikipedia.org/wiki/%EC%B9%B4%EB%B3%B5%EC%8B%9C%EA%B8%B0" title="카복시기" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">카복시기</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">를 모두 포함하고 있어, 아미노산은 중성에서&nbsp;</span><a href="https://ko.wikipedia.org/wiki/%EC%AF%94%EB%B9%84%ED%84%B0_%EC%9D%B4%EC%98%A8" class="mw-redirect" title="쯔비터 이온" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">양쪽성 이온</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">으로 존재하며, 카복실기가 공명 상태로 안정화를 취한다. 오른쪽의 구조에서<b><span style="color: rgb(9, 0, 255);"> R은 나머지라는 뜻의 "Residue" 혹은 "Remainder"의 머릿글자로 곁사슬(Side chain)을 나타내고</span></b>, 곁사슬에 무엇이 붙느냐에 따라 아미노산의 종류가 결정된다. <b><span style="color: rgb(255, 0, 0);">아미노산은 곁사슬의 성질에 따라&nbsp;</span></b></span><b><a href="https://ko.wikipedia.org/wiki/%EC%82%B0_(%ED%99%94%ED%95%99)" title="산 (화학)" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;"><span style="color: rgb(255, 0, 0);">산성</span></a><span style="color: rgb(255, 0, 0); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">,&nbsp;</span><a href="https://ko.wikipedia.org/wiki/%EC%97%BC%EA%B8%B0" title="염기" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;"><span style="color: rgb(255, 0, 0);">염기성</span></a><span style="color: rgb(255, 0, 0); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">,&nbsp;</span><a href="https://ko.wikipedia.org/wiki/%EC%B9%9C%EC%88%98%EC%84%B1" title="친수성" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;"><span style="color: rgb(255, 0, 0);">친수성</span></a><span style="color: rgb(255, 0, 0); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">(극성),&nbsp;</span><a href="https://ko.wikipedia.org/wiki/%EC%86%8C%EC%88%98%EC%84%B1" title="소수성" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;"><span style="color: rgb(255, 0, 0);">소수성</span></a></b><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);"><b><span style="color: rgb(255, 0, 0);">(무극성)의 네 가지 종류로 구분</span></b>된다</span><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질은 아미노산이 펩티드결합에 의해서 연결되어 합성됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;">20여개의 필수(9가지), 비필수 아미노산(11가지)이 있고&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;">2개의 아미노산 연결 - 다이펩타이드</span></p><p><span style="font-size: 15px; line-height: 23px;">3개 연결 - 트리펩타이드</span></p><p><span style="font-size: 15px; line-height: 23px;">50여개 연결 - 폴리펩타이드</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><b style="font-size: 15px; line-height: 23px;">2. 아미노산의 특성과 분류</b><br></p><p><span style="font-size: 15px; line-height: 23px;"><b>1) 아미노산의 특성</b></span></p><p><span style="font-size: 15px; line-height: 23px;">아미노산은 단백질의 구성단위로서 아미노산이 결합되어 단백질을 합성함. 아미노산의 화학적 구조내에 아미노기와 카르복실기를 가짐.&nbsp;가장 간단한 <b><span style="color: rgb(9, 0, 255);">아미노산은 글리신</span></b>임. <br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">아미노기는 염기성</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">카르복실기는 산성</span></b></span></p><p><br></p><p><span style="font-size: 15px; line-height: 23px;">따라서 <b><span style="color: rgb(102, 0, 255);">아미노산은 산성용액에서는 아미노기(염기성)로 작용하고&nbsp;</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(102, 0, 255);">&nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp;염기성 용액에서는 카르복실기(산성)가 작용하여 체액을 약염기성으로 중화</span></b>하는데 중요한 역할</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">대부분의<b><span style="color: rgb(0, 85, 255);"> 아미노산은 물에 잘 녹음</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;">예외) 티로신, 시스틴은 물에 잘 녹지 않음. 프롤린은 알콜에 잘 녹음</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/996BE34E5E4E8BA423" class="txc-image" actualwidth="400" hspace="1" vspace="1" border="0" width="400" exif="{}" data-filename="스크린샷 2020-02-20 오후 10.36.52.png" style="clear:none;float:none;" id="A_996BE34E5E4E8BA4232967"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>2) 아미노산의 화학적 분류</b></span></p><p><span style="font-size: 15px; line-height: 23px;">아미노산은 R기의 화학적 조성에 따라 <b><span style="color: rgb(102, 0, 255);">산성 아미노산, 중성 아미노산, 염기성 아미노산</span></b>으로 분류됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>가. 중성 아미노산</b> : 그 구조내에 1개의 아미노기와 1개의 카르복실기를 가진 것</span></p><p><span style="font-size: 15px; line-height: 23px;"># <b><span style="color: rgb(0, 85, 255);">neutral polar </span></b>: <b><span style="color: rgb(255, 0, 0);">tyrosine, serine, threonine, asparagine, glutamine, cysteine</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"># <b><span style="color: rgb(0, 85, 255);">neutral nonpolar</span></b> : <b><span style="color: rgb(255, 0, 0);">tryptophan, phenylalanine, glycine, alanine, valine, isoleucine, leucine, methione, proline</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>나.&nbsp;산성 아미노산</b> : R기에 카르복실기가 첨가된 것&nbsp;</span><span style="font-size: 15px; line-height: 23px;">- <b><span style="color: rgb(255, 0, 0);">aspartic acid, glutamic acid</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>다. 염기성 아미노산</b> : R기에 아미노기가 첨가된 것 - <b><span style="color: rgb(255, 0, 0);">lysine, arginine, histidine</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/9966694F5E8D68392C" class="txc-image" actualwidth="398" hspace="1" vspace="1" border="0" width="398" exif="{}" data-filename="스크린샷 2020-04-08 오후 2.57.56.png" style="clear:none;float:none;" id="A_9966694F5E8D68392C33BE"/></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99F1E44F5E8D683934" class="txc-image" actualwidth="398" hspace="1" vspace="1" border="0" width="398" exif="{}" data-filename="스크린샷 2020-04-08 오후 2.58.49.png" style="clear:none;float:none;" id="A_99F1E44F5E8D6839341E18"/></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99FB7E365E8D68F430" class="txc-image" actualwidth="327" hspace="1" vspace="1" border="0" width="327" exif="{}" data-filename="스크린샷 2020-04-08 오후 3.01.46.png" style="clear:none;float:none;" id="A_99FB7E365E8D68F4303CEF"/></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/996A77365E8D68F429" class="txc-image" actualwidth="364" hspace="1" vspace="1" border="0" width="364" exif="{}" data-filename="스크린샷 2020-04-08 오후 3.02.02.png" style="clear:none;float:none;" id="A_996A77365E8D68F429408B"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">중성 아미노산은 화학적 특성에 따라 <b><span style="color: rgb(9, 0, 255);">지방족 아미노산, 곁가지 아미노산, 함황 아미노산, 방향족 아미노산</span></b>으로 나뉨&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>산성 아미노산</b> - <b><span style="color: rgb(9, 0, 255);">아스파트르산, 글루타민산</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>염기성 아미노산</b> -<b><span style="color: rgb(255, 0, 0);"> 리신, 아르기닌, 히스티딘</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>중성 아미노산</b> - <span style="color: rgb(102, 0, 255);"><b>지방족 아미노산</b></span> - 글리신, 세린, 트레오닌, 아스파라긴, 글루타민, 알라닌, 프롤린</span></p><p><span style="font-size: 15px; line-height: 23px;">&nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; 곁가지 아미노산 - 발린, 류신, 이소류신</span></p><p><span style="font-size: 15px; line-height: 23px;">&nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp;&nbsp;<b><span style="color: rgb(9, 0, 255);">함황 아미노산 - 시스테인, 메티오닌</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;">&nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; &nbsp; 방향족 아미노산 - 페닐알라닌, 티로신, 트립토판</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99463C4A5E4DB8C014" class="txc-image" actualwidth="418" hspace="1" vspace="1" border="0" width="418" exif="{}" data-filename="스크린샷 2020-02-20 오전 7.37.24.png" style="clear:none;float:none;" id="A_99463C4A5E4DB8C0141D34"/></p><p></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99248E495E4E852412" class="txc-image" actualwidth="852" hspace="1" vspace="1" border="0" width="852" exif="{}" data-filename="스크린샷 2020-02-20 오후 10.08.02.png" style="clear:none;float:none;" id="A_99248E495E4E852412D0D6"/></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/996E39495E4E85240F" class="txc-image" actualwidth="866" hspace="1" vspace="1" border="0" width="866" exif="{}" data-filename="스크린샷 2020-02-20 오후 10.08.24.png" style="clear:none;float:none;" id="A_996E39495E4E85240F235D"/></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/993C8A495E4E852511" class="txc-image" actualwidth="872" hspace="1" vspace="1" border="0" width="872" exif="{}" data-filename="스크린샷 2020-02-20 오후 10.08.53.png" style="clear:none;float:none;" id="A_993C8A495E4E85251177A1"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>3) 필수아미노산과 비필수 아미노산</b><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">체내에서 합성되지 못하거나 필요량보다 적게 합성되는 아미노산은 필수 아미노산</span></p><p><span style="font-size: 15px; line-height: 23px;">체내에서 충분한 양이 합성되는 아미노산을 비필수 아미노산</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>필수 아미노산</b>&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(0, 85, 255);">히스티딘, 이소류신, 아르기닌, 메티오닌, 류신, 리신, 페닐알라닌, 트레오닌, 트립토판, 발린</span></b>.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;">&nbsp; 이중에서 <b><span style="color: rgb(255, 0, 0);">'아르기닌과 히스티딘'은 아동기에는 필수, 성인기에는 비필수 아미노산</span></b></span></p><p><br></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>비필수 아미노산</b> - <b><span style="color: rgb(0, 85, 255);">아미노산의 탄소골격은 아미노산, 탄수화물, 지질에서 생성</span></b>되며 여기에 아미노기가 다른 아미노산에 분리된 것이 합해져서 만들어짐. 이러한 과정은 특정 효소와 조효소에 의해서 만들어짐.&nbsp;</span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99CF7D425E4DB97014" class="txc-image" actualwidth="589" hspace="1" vspace="1" border="0" width="589" exif="{}" data-filename="스크린샷 2020-02-20 오전 7.40.20.png" style="clear:none;float:none;" id="A_99CF7D425E4DB970142E98"/></p><p></p><p><br></p><p><span style="font-size: 11pt;"><b>포도당생성 아미노산</b></span><br></p><p><span style="font-size: 11pt;">피루베이트(포도당) &lt;- 알라닌, 발린, 류신</span></p><p><span style="font-size: 11pt;">3-phosphoglycerate(포도당) &lt;- 세린, 시스테인, 글라이신</span></p><p><span style="font-size: 11pt;">옥살로아세이트(구연산회로) &lt;- 아스파라닌, 메티오닌, 트레오닌, 이소류신, 리신</span></p><p><span style="font-size: 11pt;">알파-케토글루타레이트(구연산회로)&lt;-페닐알라닌, 글루타민, 프롤린, 아르기닌</span></p><p><span style="font-size: 11pt;">phosphoenolypyruvate+erythros 4 phosphate &lt;- 페닐알라닌, 타이로신, 트립토판</span></p><p><span style="font-size: 11pt;">ribos 5- phosphate &lt;- 히스티딘</span></p><p><span style="font-size: 11pt;"><br></span></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/9948AE4F5E4E88DE1F" class="txc-image" actualwidth="802" hspace="1" vspace="1" border="0" width="802" exif="{}" data-filename="스크린샷 2020-02-20 오후 10.24.44.png" style="clear:none;float:none;" id="A_9948AE4F5E4E88DE1F50F7"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>3. 단백질의 구조와 분류</b></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질은 아미노산이 수십개, 수백개 결합하여 합성됨. 아미노산이 연결되어 폴리펩티드를 이루면서 여러 형태를 가지며 고유의 작용을 함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>1) 단백질의 4가지 구조</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b></b><br></span></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99F896505E4E8CFF1C" class="txc-image" actualwidth="591" hspace="1" vspace="1" border="0" width="591" exif="{}" data-filename="스크린샷 2020-02-20 오후 10.42.43.png" style="clear:none;float:none;" id="A_99F896505E4E8CFF1CD82E"/></p><p><span style="font-size: 15px; line-height: 23px;"><b><br></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b></b><br></span></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99B2473A5E4E8AEF39" class="txc-image" actualwidth="494" hspace="1" vspace="1" border="0" width="494" exif="{}" data-filename="스크린샷 2020-02-20 오후 10.34.15.png" style="clear:none;float:none;" id="A_99B2473A5E4E8AEF39B7F3"/></p><p><span style="font-size: 15px; line-height: 23px;"><b><br></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><br></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>가. 1차구조</b></span></p><p><span style="font-size: 15px; line-height: 23px;">1차구조는 <b><span style="color: rgb(9, 0, 255);">아미노산의 종류와 배합순서가 결정되어 폴리펩티드 결합</span></b>으로 이어진 구조를 이룸. 아미노산의 결합순서는 단백질마다 다름. <b><span style="color: rgb(255, 0, 0);">헤모글로빈, 인슐린, 콜라겐 등 대부분의 단백질 분자는 10~15가지의 아미노산을 함유</span></b>하고 있음. <b><span style="color: rgb(0, 85, 255);">인슐린은 한가닥의 폴리펩티드 사슬이 2개의 이황화 결합으로 연결된 구조</span></b>임. 수십개 이상의 아미노산이 결합하여 폴리펩티드가 형성되면 이 폴리펩티드 사슬간에 이황화 결합(Disulfide bond)으로 이루어진 폴리펩티드가 형성되어 이 폴리펩티드를 안정화함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>나. 2차구조</b></span></p><p><span style="font-size: 15px; line-height: 23px;">1차 구조로 생긴 폴리펩티드 사슬이 2차 구조인 <b><span style="color: rgb(255, 0, 0);">나선구조 알파나, 병풍구조 베타</span></b>를 이룸. 이러한 결합은 폴리펩티드 사슬내에서 또는 폴리펩티드 사슬간의 수소결합에 의해 안정화됨</span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99878F4B5E4E8A5014" class="txc-image" actualwidth="524" hspace="1" vspace="1" border="0" width="524" exif="{}" data-filename="스크린샷 2020-02-20 오후 10.31.22.png" style="clear:none;float:none;" id="A_99878F4B5E4E8A5014D2E6"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>다. 3차구조</b></span></p><p><span style="font-size: 15px; line-height: 23px;">3차구조는 폴리펩티드 사슬이 떨어져 있는 <b><span style="color: rgb(9, 0, 255);">아미노산 잔기들과 여러가지 상호작용 결과 구조가 서로 접히고 꼬임으로써 생리작용을 완수할 수 있는 특수한 단백질 구조</span></b>를 이룸. <b><span style="color: rgb(255, 0, 0);">섬유형 단백질과 구형 단백질</span></b>이 있음.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>라. 4차구조</b></span></p><p><span style="font-size: 15px; line-height: 23px;">4차구조는 <b><span style="color: rgb(255, 0, 0);">두개 이상의 폴리펩티드나 단백질이 수소결합과 같은 상호작용으로 연결</span></b>되어 한 분자의 구조적 기능단위를 형성함. 헤모글로빈은 두쌍의 소단위로 구성되며 네개의 폴리펩티드로 이루어짐.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99777F4C5E4E8BF907" class="txc-image" actualwidth="533" hspace="1" vspace="1" border="0" width="533" exif="{}" data-filename="스크린샷 2020-02-20 오후 10.38.30.png" style="clear:none;float:none;" id="A_99777F4C5E4E8BF907A39B"/></p><p><span style="font-size: 15px; line-height: 23px;"><b>2) 단백질의 화학적 분류<br></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>가. 단순 단백질</b></span></p><p><span style="font-size: 15px; line-height: 23px;">단순단백질은<b><span style="color: rgb(255, 0, 0);"> 가수분해에 의해서 단순 아미노산과 그 유도체를 생성</span></b>함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">알부민 - 달걀 알부민, 혈청 알부민, 밀의 류코신, 완두콩의 레구멜린</span></p><p><span style="font-size: 15px; line-height: 23px;">글로불린 - 근육과 혈청 글로불린, 콩의 글리신, 완두콩의 레구민, 감자의 투버린, 땅콩의 아라긴</span></p><p><span style="font-size: 15px; line-height: 23px;">글루텔린 - 밀의 글루테닌, 쌀의 오리제닌</span></p><p><span style="font-size: 15px; line-height: 23px;">프롤라민 - 밀의 글리아딘, 옥수수의 제인, 보리의 호르데인</span></p><p><span style="font-size: 15px; line-height: 23px;">알부미노이드 - 뼈의 콜라겐, 모발의 케라틴</span></p><p><span style="font-size: 15px; line-height: 23px;">히스톤 - 혈액의 글로빈, 흉선의 히스톤</span></p><p><span style="font-size: 15px; line-height: 23px;">프로타민 - 연어 정액중의 실민, 정어리 정액중의 클루페인</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;"><font size="4" face="verdana"><b>Albumin in critically ill patients: controversies and recommendations&nbsp;</b></font></p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;">&nbsp;</p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;">&nbsp;</p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;"><font size="2" face="Verdana"><b>Haroldo Falc&#227;o<sup>I,II</sup>; Andr&#233; Miguel Japiass&#250;<sup>I,III</sup></b></font></p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;"><font size="2" face="Verdana"><sup>I</sup>Hospital Quinta D´Or, Labs D'Or Network - Rio de Janeiro (RJ), Brazil<br><sup>II</sup>Intensive Care Unit of Hospital Central da Pol&#237;cia Militar do Estado do Rio de Janeiro &#8211; Rio de Janeiro (RJ), Brazil<br><sup>III</sup>Intensive Care Unit of Instituto de Pesquisa Cl&#237;nica Evandro Chagas - FIOCRUZ &#8211; Rio de Janeiro (RJ), Brazil</font></p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;"><a href="http://www.scielo.br/scielo.php?pid=S0103-507X2011000100014&amp;script=sci_arttext&amp;tlng=en#nt"><font size="2" face="Verdana">Corresponding author</font></a></p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;">&nbsp;</p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;">&nbsp;</p><hr size="1" noshade="" style="color: rgb(0, 0, 0); font-family: verdana, arial; font-size: 14px; line-height: normal;"><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;"><font size="2" face="Verdana"><b>ABSTRACT&nbsp;</b></font></p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;"><font size="2" face="Verdana"><b><span style="color: rgb(255, 0, 0);">Human albumin has been used as a therapeutic agent in intensive care units for more than 50 years</span></b>. However, clinical studies from the late 1990s described possible harmful effects in critically ill patients. These studies' controversial results followed other randomized controlled studies and metaanalyses that showed no harmful effects of this colloid solution. In Brazil, several public and private hospitals comply with the Ag&#234;ncia Nacional de Vigil&#226;ncia Sanit&#225;ria (the Brazilian Health Surveillance Agency) recommendations for appropriate administration of intravenous albumin. T<b><span style="color: rgb(0, 85, 255);">his review discusses indications for albumin administration in critically ill patients and analyzes the evidence for metabolic and immunomodulatory effects of this colloid solution.</span></b> We also describe the most significant studies from 1998 to the present time; these reveal an absence of incremental mortality from intravenous albumin administration as compared to crystalloid solutions.<b><span style="color: rgb(255, 0, 0);"> The National Health Surveillance Agency indications are discussed relative to the current body of evidence for albumin use in critically ill patients</span></b>.&nbsp;</font></p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;"><font size="2" face="Verdana"><br></font></p><p style="font-size: 13px; color: rgb(0, 0, 0); font-family: verdana, arial; line-height: normal;"><font size="2" face="Verdana"><b>Keywords:&nbsp;</b>Albumin; Edema; Sepsis; Hypovolemia; Colloid osmotic pressure; Hypoalbuminemia; Therapeutics; Prognosis</font></p><p><br></p><p><span style="font-size: 11pt;"><b>알부민의 기능</b></span></p><p><span style="font-size: 11pt;">1) intravascular pressure 유지</span></p><p><span style="font-size: 11pt;">2) 산-염기 평형유지</span></p><p><span style="font-size: 11pt;">3) 항산화작용</span></p><p><span style="font-size: 11pt;">4) drug 운반</span></p><p><span style="font-size: 11pt;">5) 영양소 운반(지방산, 빌리루빈, 호르몬 등)</span></p><p><span style="font-size: 11pt;">6) 항응고 작용</span></p><p><span style="font-size: 11pt;">7) microvascular integrity</span></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99470E4A5E4EE78F0F" class="txc-image" actualwidth="430" hspace="1" vspace="1" border="0" width="430" exif="{}" data-filename="스크린샷 2020-02-21 오전 5.09.28.png" style="clear:none;float:none;" id="A_99470E4A5E4EE78F0F933A"/></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/997C333B5E4EE81F12" class="txc-image" actualwidth="434" hspace="1" vspace="1" border="0" width="434" exif="{}" data-filename="스크린샷 2020-02-21 오전 5.11.53.png" style="clear:none;float:none;" id="A_997C333B5E4EE81F122130"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p></p><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: &quot;Times New Roman&quot;, stixgeneral, serif; font-size: 15.9991px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial;"></div><div id="idm139805556797056" lang="en" class="tsec sec" style="clear: both; display: none; color: rgb(0, 0, 0); font-family: &quot;Times New Roman&quot;, stixgeneral, serif; font-size: 15.9991px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial;"><div class="goto jig-ncbiinpagenav-goto-container" style="float: right; text-align: right; font-family: arial, helvetica, clean, sans-serif; font-size: 0.86666em !important;"><span role="menubar"><a class="tgt_dark page-toc-label jig-ncbiinpagenav-goto-heading" href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3577569/#" title="Go to other sections in this page" role="menuitem" aria-expanded="false" aria-haspopup="true" style="background: url(&quot;//static.pubmed.gov/portal/portal3rc.fcgi/4160049/img/2846531&quot;) 100% 43.5% no-repeat transparent; padding-right: 17px; margin-right: 3px; text-decoration: none; color: rgb(100, 42, 143);">Go to:</a></span></div><h2 class="head no_bottom_margin ui-helper-clearfix" id="idm139805556797056title" style="font-size: 1.125em; line-height: 1.1111em; margin: 1.125em 0px 0px; color: rgb(152, 87, 53); min-height: 0px; display: block; border-bottom: 1px solid rgb(151, 176, 200); font-family: arial, helvetica, clean, sans-serif; font-weight: normal;">Abstract</h2><div><p id="__p1" class="p p-first-last" style="margin: 0.6923em 0px;">Human serum albumin (HSA) has been used for a long time as a resuscitation fluid in critically ill patients. It is known to exert several important physiological and pharmacological functions. Among them, the antioxidant properties seem to be of paramount importance as they may be implied in the potential beneficial effects that have been observed in the critical care and hepatological settings. The specific antioxidant functions of the protein are closely related to its structure. Indeed, they are due to its multiple ligand-binding capacities and free radical-trapping properties. The HSA molecule can undergo various structural changes modifying its conformation and hence its binding properties and redox state. Such chemical modifications can occur during bioprocesses and storage conditions of the commercial HSA solutions, resulting in heterogeneous solutions for infusion. In this review, we explore the mechanisms that are responsible for the specific antioxidant properties of HSA in its native form, chemically modified forms, and commercial formulations. To conclude, we discuss the implication of this recent literature for future clinical trials using albumin as a drug and for elucidating the effects of HSA infusion in critically ill patients.</p></div><div class="sec" style="clear: both;"><strong class="kwd-title" style="font-weight: bold;">Keywords:<span>&nbsp;</span></strong><span class="kwd-text"></span></div></div><p></p><div class="fm-sec half_rhythm no_top_margin" style="margin: 0px 0px 0.6923em; font-style: normal; font-variant: normal; font-size: 0.8425em; line-height: 1.6363em; font-family: arial, helvetica, clean, sans-serif; color: rgb(0, 0, 0); letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);"><h1 class="content-title" style="font-size: 1.5384em; margin: 1em 0px 0.5em; line-height: 1.35em; color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif;"><span style="font-size: 12pt; color: rgb(0, 85, 255);">Specific antioxidant properties of human serum albumin</span></h1><div class="half_rhythm" style="font-weight: 400; margin: 0.6923em 0px;"><div class="contrib-group fm-author"><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Taverna%20M%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=23414610" id="A1" class="affpopup" co-rid="_co_idm139805594472240" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Myriam Taverna</a>,<sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;"><img src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fwww.ncbi.nlm.nih.gov%2Fcorehtml%2Fpmc%2Fpmcgifs%2Fcorrauth.gif" alt="corresponding author" style="max-width: 100%; border: 0px;"></sup><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">1,</sup><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">2</sup><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Marie%20AL%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=23414610" id="A2" class="affpopup" co-rid="_co_idm139805554225360" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Anne-Lise Marie</a>,<sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">1,</sup><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">2</sup><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Mira%20JP%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=23414610" id="A3" class="affpopup" co-rid="_co_idm139805557323456" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Jean-Paul Mira</a>,<sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">3,</sup><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">4,</sup><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">5</sup><span>&nbsp;</span>and<span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Guidet%20B%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=23414610" id="A4" class="affpopup" co-rid="_co_idm139805551380976" co-class="co-affbox" canvas-rid="_cid__co_idm139805551380976" style="white-space: nowrap; color: rgb(100, 42, 143);">Bertrand Guidet</a><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">6,</sup><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">7,</sup><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">8</sup></div></div><div class="fm-panel half_rhythm" style="font-weight: 400; margin: 0.6923em 0px;"><div class="togglers"><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3577569/#" class="pmctoggle" rid="idm139805597175744_ai" style="text-decoration: none; color: rgb(100, 42, 143);">Author information</a><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3577569/#" class="pmctoggle" rid="idm139805597175744_an" style="text-decoration: none; color: rgb(100, 42, 143);">Article notes</a><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3577569/#" class="pmctoggle" rid="idm139805597175744_cpl" style="text-decoration: none; color: rgb(100, 42, 143);">Copyright and License information</a><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/about/disclaimer/" style="color: rgb(100, 42, 143);">Disclaimer</a></div></div><div id="pmclinksbox" class="links-box whole_rhythm" style="font-weight: 400; border: 1px solid rgb(234, 195, 175); background-color: rgb(255, 244, 206); padding: 0.3923em 0.6923em; margin: 1.3846em 0px; border-top-left-radius: 5px; border-top-right-radius: 5px; border-bottom-right-radius: 5px; border-bottom-left-radius: 5px;"><div class="fm-panel"><div>This article has been<span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3577569/citedby/" style="color: rgb(100, 42, 143);">cited by</a><span>&nbsp;</span>other articles in PMC.</div></div></div></div><h2 class="head no_bottom_margin ui-helper-clearfix" id="idm139805556797056title" style="font-size: 1.125em; line-height: 1.1111em; margin: 1.125em 0px 0px; color: rgb(152, 87, 53); min-height: 0px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(151, 176, 200); font-family: arial, helvetica, clean, sans-serif; font-weight: normal; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">Abstract</h2><div style="color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 15.9991px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><p id="__p1" class="p p-first-last" style="margin-top: 0.6923em; margin-bottom: 0.6923em;"><b><span style="color: rgb(255, 0, 0);">Human serum albumin (HSA) has been used for a long time as a resuscitation fluid in critically ill patients</span></b>. It is known to exert several important physiological and pharmacological functions. Among them, the antioxidant properties seem to be of paramount importance as they may be implied in the potential beneficial effects that have been observed in the critical care and hepatological settings. The specific antioxidant functions of the protein are closely related to its structure. Indeed, they are due to its multiple ligand-binding capacities and free radical-trapping properties. The HSA molecule can undergo various structural changes modifying its conformation and hence its binding properties and redox state. Such chemical modifications can occur during bioprocesses and storage conditions of the commercial HSA solutions, resulting in heterogeneous solutions for infusion. In this review, we explore the <b><span style="color: rgb(9, 0, 255);">mechanisms that are responsible for the specific antioxidant properties of HSA in its native form, chemically modified forms, and commercial formulations</span></b>. To conclude, we discuss the implication of this recent literature for future clinical trials using albumin as a drug and for elucidating the effects of HSA infusion in critically ill patients.</p></div><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 15.9991px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><strong class="kwd-title">Keywords:&nbsp;</strong><span class="kwd-text">Human serum albumin, Antioxidant force, Oxidized albumin, Critically ill patients</span></div><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 15.9991px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><span class="kwd-text"><br></span></div><p><span style="font-size: 15px; line-height: 23px;"><b>나. 복합 단백질</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>핵단백질</b> - 핵산과 단백질이 결합된 것으로 세포핵의 주성분. 흉선의 뉴클레오히스톤, 어류 정액의 뉴클레오프로타민, <b><span style="color: rgb(255, 0, 0);">핵산 RNA와 DNA</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>당단백질</b> - <b><span style="color: rgb(255, 0, 0);">당질 또는 그 유도체와 단백질이 결합</span></b>한 것. 우유의 카세인과 달걀 노른자의 오보비텔린</span></p><p><span style="font-size: 15px; line-height: 23px;"><b>지단백질</b> - <b><span style="color: rgb(255, 0, 0);">킬로미크론, LDL, VLDL, HDL</span></b>. 달걀 노른자의 리포비텔린과 리포베틸리닌</span></p><p><span style="font-size: 15px; line-height: 23px;"><b>색소단백질</b> - 색소와 단백질이 결합된 것. <b><span style="color: rgb(255, 0, 0);">체내의 산화 환원에 중요한 역할. 헤모글로빈, 미오글로빈</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>미오글로빈</b> - 체조직 내 카탈라아제나 퍼옥시다아제 등의 산화효소, 플라보프로테인, NAD(니코틴아미드아데닌 디뉴클레오티드)</span></p><p><span style="font-size: 15px; line-height: 23px;"><b>금속단백질</b> - <b><span style="color: rgb(9, 0, 255);">철, 구리, 아연과 단백질이 결합된 것</span></b>. 철단백질 페리틴, 구리단백질 헤모시아닌, 연체동물의 혈액내 아연단백질인 인슐린(췌장호르몬), 마그네슘 함유의 클로로필 프로테인</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">참고) 헤모시아닌- 해양무척추동물이 산소 운반체로 쓰는 금속단백질(헤모글로빈과 달리 구리를 가짐)</span></p><p><span style="font-size: 15px; line-height: 23px;">참고) 클로로필 - 엽록소. 일종의 포르피린 화합물이며 헤모글로빈이 철을 함유하는 대신 마그네슘 함유</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">참고)&nbsp;</span><b style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;">Glycoproteins</b><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;are&nbsp;</span><a href="https://en.wikipedia.org/wiki/Protein" title="Protein" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">proteins</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;which contain&nbsp;</span><a href="https://en.wikipedia.org/wiki/Oligosaccharide" title="Oligosaccharide" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">oligosaccharide</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;chains (</span><a href="https://en.wikipedia.org/wiki/Glycans" class="mw-redirect" title="Glycans" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">glycans</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">)&nbsp;</span><a href="https://en.wikipedia.org/wiki/Covalent_bond" title="Covalent bond" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">covalently</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;attached to&nbsp;</span><a href="https://en.wikipedia.org/wiki/Amino_acid" title="Amino acid" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">amino acid</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;side-chains. The carbohydrate is attached to the protein in a&nbsp;</span><a href="https://en.wikipedia.org/wiki/Translation_(genetics)" class="mw-redirect" title="Translation (genetics)" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">cotranslational</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;or&nbsp;</span><a href="https://en.wikipedia.org/wiki/Posttranslational_modification" class="mw-redirect" title="Posttranslational modification" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">post-translational modification</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">. This process is known as&nbsp;</span><a href="https://en.wikipedia.org/wiki/Glycosylation" title="Glycosylation" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">glycosylation</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">.&nbsp;</span><a href="https://en.wikipedia.org/wiki/Secretory_protein" title="Secretory protein" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">Secreted extracellular proteins</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;are often glycosylated.</span></p><p><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);"><br></span></p><p><br></p><p style="text-align: center;"></p><p><b style="font-size: 15px; line-height: 23px;">다. 유도 단백질</b><br></p><p><span style="font-size: 15px; line-height: 23px;">유도단백질은 단순단백질 또는 복합단백질이 산, 알칼리, 효소의 작용이나 가열에 의해 변성된 것을 말하며 변화정도에 따라 1차 유도단백질과 2차 유도단백질로 나뉨.</span></p><p><br></p><p><span style="font-size: 15px; line-height: 23px;"># 1차 유도단백질 - 파라카세인, 젤라틴, 응고단백질</span></p><p><span style="font-size: 15px; line-height: 23px;"># 2차 유도단백질 - 1차 유도단백질이 가수분해되어 생성된 것으로 프로테오스, 펩톤, 펩티드&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>3) 단백질의 영양적, 형태적 분류</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>가. 영양적 분류</b></span></p><p><br></p><p><span style="font-size: 15px; line-height: 23px;"><b># 완전 단백질</b> - <b><span style="color: rgb(255, 0, 0);">정상적 성장을 돕고 체중을 증가시키며 생리적 기능을 도움</span></b>. 이는 완전단백질이 모든 필수아미노산을 충분히 함유하고 있기 때문임. 완전 단백질에 속하는 단백질은 우유의 카세인과 락트알부민, 달걀의 오브알부민, 콩의 글리시닌, 보리의 에데스틴, 밀의 글루테닌과 글루텔린</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 부분적 불완전 단백질</b> - 성장을 돕지는 못하지만 체중을 유지시키는 작용. 이 단백질에는<b><span style="color: rgb(102, 0, 255);"> 밀의 글리아딘,</span></b> 보리의 호르데인, 귀리의 프롤라민</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 불완전 단백질</b> - 단백질 급원으로 이것만 섭취하면 성장 지연, 체중감소하는 단백질. 젤라틴, 옥수수의 제인 등이 그것임.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>나. 형태적 분류&nbsp;</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(0, 85, 255);"># 구상 단백질</span></b> - <b><span style="color: rgb(9, 0, 255);">구형으로 소수성 및 친수성 상호작용에 의해 전체적으로 구형</span></b>구조임. <b><span style="color: rgb(255, 0, 0);">구상 단백</span><span style="color: rgb(255, 0, 0);">질은 수용성으로 대부분의 효소, 단백호르몬과 혈장 단백질 등</span></b>이 그 예임. 구상 단백질 중 영양적으로 중요한 것은 '<b><span style="color: rgb(255, 0, 0);">카세인, 달걀 알부민, 혈청 알부민과 글로불린, 헤모글로빈, 생리활성물질</span></b> 등</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99937F3A5E4EE73E11" class="txc-image" actualwidth="529" hspace="1" vspace="1" border="0" width="529" exif="{}" data-filename="스크린샷 2020-02-21 오전 5.08.06.png" style="clear:none;float:none;" id="A_99937F3A5E4EE73E111ED8"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(0, 85, 255);"># 섬유상 단백질</span></b> - <b><span style="color: rgb(255, 0, 0);">물에 용해되지 않으며</span></b> 세포조직의 유지나 구조를 이루는 물질. <b><span style="color: rgb(255, 0, 0);">콜라겐, 엘라스틴, </span></b>명주실의 피브로인 등</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99B0024D5E4EE65910" class="txc-image" actualwidth="509" hspace="1" vspace="1" border="0" width="509" exif="{}" data-filename="스크린샷 2020-02-21 오전 5.04.11.png" style="clear:none;float:none;" id="A_99B0024D5E4EE659105615"/></p><p><span style="font-size: 15px; line-height: 23px;"><b>참고) 글루텐 단백질의 구조</b></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99EF67415E5598CB17" class="txc-image" actualwidth="360" hspace="1" vspace="1" border="0" width="360" exif="{}" data-filename="스크린샷 2020-02-26 오전 6.58.42.png" style="clear:none;float:none;" id="A_99EF67415E5598CB1738F2"/></p><p></p><p style="margin-top: 0.4em; margin-bottom: 0.5em; line-height: 19.049999237060547px; color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px;"><br></p><p style="margin-top: 0.4em; margin-bottom: 0.5em; line-height: 19.049999237060547px; color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px;">The protein&nbsp;<a href="https://en.wikipedia.org/wiki/Gluten" class="external text" title="https://en.wikipedia.org/wiki/Gluten" rel="nofollow" target="_blank" style="color: rgb(51, 102, 187); background-image: url(https://proteopedia.org/wiki/skins/monobook/lock_icon.gif); padding-right: 16px; background-position: 100% 50%; background-repeat: no-repeat no-repeat;">gluten</a>&nbsp;is found in wheat and grains such as rye and barley.<b><span style="color: rgb(255, 0, 0);"> Gluten is also involved with inducing an inflammatory response in individuals with&nbsp;</span><a href="https://en.wikipedia.org/wiki/Coeliac_disease" class="external text" title="https://en.wikipedia.org/wiki/Coeliac_disease" rel="nofollow" target="_blank" style="color: rgb(51, 102, 187); background-image: url(https://proteopedia.org/wiki/skins/monobook/lock_icon.gif); padding-right: 16px; background-position: 100% 50%;"><span style="color: rgb(255, 0, 0);">celiac disease</span></a></b>. Individuals who have the disease cannot digest gluten due to the structure of the protein, which will damage the small intestine. If an individual with&nbsp;<b>celiac disease</b>&nbsp;ingests foods containing gluten, the immune system responds by damaging the villi, which are fingerlike projections lining the small intestine. This immune response reduces the body’s ability to absorb nutrients that pass through the small intestine and into the bloodstream. As a result of the damaged villi, people with celiac disease can become malnourished. Although celiac disease is genetic, the research reviewed for this study placed emphasis on how the protein triggers an immune response in the gastrointestinal tract of affected individuals.</p><p><b style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">Gluten</b><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">is a protein complex comprised of 2 components:</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><b style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">gliadin</b><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">(the water-soluble component) and</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><b style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">glutenin</b><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">(the water-isoluble component). Gliadins, for those with celiac disease, are the principle toxic component of gluten and are composed of proline and glutamine-rich peptide sequences. The peptides enter the circulatory system and come into contact with</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><a href="https://en.wikipedia.org/wiki/Lymphocyte" class="external text" title="https://en.wikipedia.org/wiki/Lymphocyte" rel="nofollow" target="_blank" style="font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px; color: rgb(51, 102, 187); background-image: url(https://proteopedia.org/wiki/skins/monobook/lock_icon.gif); padding-right: 16px; background-position: 100% 50%;">lymphocytes</a><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">and</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><a href="https://en.wikipedia.org/wiki/T_cell" class="external text" title="https://en.wikipedia.org/wiki/T_cell" rel="nofollow" target="_blank" style="font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px; color: rgb(51, 102, 187); background-image: url(https://proteopedia.org/wiki/skins/monobook/lock_icon.gif); padding-right: 16px; background-position: 100% 50%;">T-cells</a><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">, resulting in the release of cytokines. The</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><a href="https://en.wikipedia.org/wiki/Cytokine" class="external text" title="https://en.wikipedia.org/wiki/Cytokine" rel="nofollow" target="_blank" style="font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px; color: rgb(51, 102, 187); background-image: url(https://proteopedia.org/wiki/skins/monobook/lock_icon.gif); padding-right: 16px; background-position: 100% 50%;">cytokines</a><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">&nbsp;</span><span style="color: rgb(0, 0, 0); font-family: sans-serif; font-size: 13px; line-height: 19.049999237060547px;">interact with the villi of the small intestine and damage them, disabling the body from nutrient absorption. The symptoms can include abdominal pain, weight loss, fatigue, and many other symptoms associated with malnutrition. As of now, the only treatment for celiac disease is the total exclusion of gluten from the person’s diet.</span><sup id="cite_ref-0" class="reference" style="color: rgb(0, 0, 0); font-family: sans-serif; line-height: 1em;"><a href="https://proteopedia.org/wiki/index.php/Gluten#cite_note-0" title="" style="color: rgb(90, 54, 150); background-image: none;">[</a></sup><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>4. 단백질의 소화와 흡수</b></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질의 소화는 위와 소장에서 이루어짐. <b><span style="color: rgb(255, 0, 0);">단백질의 소화는 변성이 일어나서 단백질 2, 3, 4차 구조가 깨지고 폴리펩티드 사슬구조로 된 후 시작됨. 변성된 단백질에 소화효소가 작용하여 펩티드 결합이 분해되고 아미노산으로 완전 소화</span></b>됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">참고) <b><span style="color: rgb(0, 85, 255);">폴리펩타이드는 50여개의 아미노산 연결</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99D430335E543BCC0E" class="txc-image" actualwidth="422" hspace="1" vspace="1" border="0" width="422" exif="{}" data-filename="스크린샷 2020-02-25 오전 6.10.06.png" style="clear:none;float:none;" id="A_99D430335E543BCC0E866C"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>1) 소화</b></span></p><p><span style="font-size: 15px; line-height: 23px;">음식에 들어있는 단백질은 주로 위와 소장에서 소화가 이루어지며<b><span style="color: rgb(255, 0, 0);"> 분해된 아미노산은 소장에서 흡수되어 간으로 운반</span></b>됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/997A22385E4EE5F310" class="txc-image" actualwidth="988" hspace="1" vspace="1" border="0" width="988" exif="{}" data-filename="스크린샷 2020-02-21 오전 5.01.24.png" style="clear:none;float:none;" id="A_997A22385E4EE5F31037E1"/></p><p style="text-align: left;"><br></p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;"><b><span style="font-size: 11pt;">There are several families that function in amino acid transport, some of these include:</span></b></span></p><ul style="list-style-image: url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/bullet-icon.svg?872f1); margin: 0.3em 0px 0px 1.6em; padding: 0px; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;"><li style="margin-bottom: 0.1em;"><a rel="nofollow" class="external text" href="http://www.tcdb.org/search/result.php?tc=2.A.3" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); padding-right: 13px; background-position: 100% 50%, 100% 50%; background-repeat: no-repeat no-repeat;">TC# 2.A.3</a>&nbsp;-&nbsp;<a href="https://en.wikipedia.org/wiki/APC_Superfamily" class="mw-redirect" title="APC Superfamily" style="color: rgb(11, 0, 128); background-image: none;">Amino Acid-Polyamine-Organocation (APC) Superfamily</a></li><li style="margin-bottom: 0.1em;"><a rel="nofollow" class="external text" href="http://www.tcdb.org/search/result.php?tc=2.A.18" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); padding-right: 13px; background-position: 100% 50%, 100% 50%; background-repeat: no-repeat no-repeat;">TC# 2.A.18</a>&nbsp;-&nbsp;<a href="https://en.wikipedia.org/wiki/AAAP_Family" class="mw-redirect" title="AAAP Family" style="color: rgb(11, 0, 128); background-image: none;">Amino Acid/Auxin Permease (AAAP) Family</a></li><li style="margin-bottom: 0.1em;"><a rel="nofollow" class="external text" href="http://www.tcdb.org/search/result.php?tc=2.A.23" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); padding-right: 13px; background-position: 100% 50%, 100% 50%; background-repeat: no-repeat no-repeat;">TC# 2.A.23</a>&nbsp;- Dicarboxylate/Amino Acid:Cation (Na<sup style="line-height: 1; font-size: 11px;">+</sup>&nbsp;or H<sup style="line-height: 1; font-size: 11px;">+</sup>) Symporter (DAACS) Family</li><li style="margin-bottom: 0.1em;"><a rel="nofollow" class="external text" href="http://www.tcdb.org/search/result.php?tc=2.A.26" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); padding-right: 13px; background-position: 100% 50%, 100% 50%; background-repeat: no-repeat no-repeat;">TC# 2.A.26</a>&nbsp;-&nbsp;<a href="https://en.wikipedia.org/wiki/BCAA:Cation_Symporter" class="mw-redirect" title="BCAA:Cation Symporter" style="color: rgb(11, 0, 128); background-image: none;">Branched Chain Amino Acid:Cation Symporter (LIVCS) Family</a></li><li style="margin-bottom: 0.1em;"><a rel="nofollow" class="external text" href="http://www.tcdb.org/search/result.php?tc=2.A.42" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); padding-right: 13px; background-position: 100% 50%, 100% 50%; background-repeat: no-repeat no-repeat;">TC# 2.A.42</a>&nbsp;-&nbsp;<a href="https://en.wikipedia.org/wiki/HAAAP_family" title="HAAAP family" style="color: rgb(11, 0, 128); background-image: none;">Hydroxy/Aromatic Amino Acid Permease (HAAAP) Family</a></li><li style="margin-bottom: 0.1em;"><a rel="nofollow" class="external text" href="http://www.tcdb.org/search/result.php?tc=2.A.78" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); padding-right: 13px; background-position: 100% 50%, 100% 50%; background-repeat: no-repeat no-repeat;">TC# 2.A.78</a>&nbsp;- Branched Chain Amino Acid Exporter (LIV-E) Family</li><li style="margin-bottom: 0.1em;"><a rel="nofollow" class="external text" href="http://www.tcdb.org/search/result.php?tc=2.A.95" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); padding-right: 13px; background-position: 100% 50%, 100% 50%; background-repeat: no-repeat no-repeat;">TC# 2.A.95</a>&nbsp;-&nbsp;<a href="https://en.wikipedia.org/wiki/6TMS_neutral_amino_acid_transporter_family" title="6TMS neutral amino acid transporter family" style="color: rgb(11, 0, 128); background-image: none;">6TMS Neutral Amino Acid Transporter (NAAT) Family</a></li><li style="margin-bottom: 0.1em;"><a rel="nofollow" class="external text" href="http://www.tcdb.org/search/result.php?tc=2.A.118" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); padding-right: 13px; background-position: 100% 50%, 100% 50%; background-repeat: no-repeat no-repeat;">TC# 2.A.118</a>&nbsp;-&nbsp;<a href="https://en.wikipedia.org/wiki/Basic_amino_acid_antiporter_family" title="Basic amino acid antiporter family" style="color: rgb(11, 0, 128); background-image: none;">Basic Amino Acid Antiporter (ArcD) Family</a></li><li style="margin-bottom: 0.1em;"><a rel="nofollow" class="external text" href="http://www.tcdb.org/search/result.php?tc=2.A.120" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(https://en.wikipedia.org/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); padding-right: 13px; background-position: 100% 50%, 100% 50%; background-repeat: no-repeat no-repeat;">TC# 2.A.120</a>&nbsp;-&nbsp;<a href="https://en.wikipedia.org/wiki/Putative_Amino_Acid_Permease" class="mw-redirect" title="Putative Amino Acid Permease" style="color: rgb(11, 0, 128); background-image: none;">Putative Amino Acid Permease (PAAP) Family</a></li></ul><div><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;"><br></p><div class="fm-sec half_rhythm no_top_margin" style="margin: 0px 0px 0.6923em; font-size: 0.8425em; line-height: 1.6363em; font-family: arial, helvetica, clean, sans-serif; color: rgb(0, 0, 0);"><div class="fm-citation half_rhythm no_top_margin clearfix" style="margin: 0px 0px 0.6923em; zoom: 1;"><div class="inline_block eight_col va_top" style="max-width: 100%; vertical-align: top; display: inline-block; zoom: 1; width: 452.3125px;"><div><span class="cit"><span role="menubar"><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5726373/#" role="menuitem" aria-expanded="false" aria-haspopup="true" style="color: rgb(100, 42, 143);">Drug Des Devel Ther</a></span>. 2017; 11: 3511&#8211;3517.&nbsp;</span></div><div><span class="fm-vol-iss-date">Published online 2017 Dec 8.&nbsp;</span><span class="doi" style="white-space: nowrap;">doi:&nbsp;<a href="https://dx.doi.org/10.2147%2FDDDT.S151725" target="pmc_ext" ref="reftype=other&amp;article-id=5726373&amp;issue-id=281802&amp;journal-id=958&amp;FROM=Article%7CFront%20Matter&amp;TO=Content%20Provider%7CCrosslink%7CDOI" style="color: rgb(100, 42, 143);">10.2147/DDDT.S151725</a></span></div></div><div class="inline_block four_col va_top show-overflow align_right" style="max-width: 100%; vertical-align: top; text-align: right; display: inline-block; zoom: 1; width: 222.703125px;"><div class="fm-citation-ids"><div class="fm-citation-pmcid"><span class="fm-citation-ids-label">PMCID:&nbsp;</span>PMC5726373</div><div class="fm-citation-pmid">PMID:&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pubmed/29263649" style="color: rgb(100, 42, 143);">29263649</a></div></div></div></div><h1 class="content-title" style="font-size: 1.5384em; margin: 1em 0px 0.5em; line-height: 1.35em; font-weight: normal;">Regulation profile of the intestinal peptide transporter 1 (PepT1)</h1><div class="half_rhythm" style="margin: 0.6923em 0px;"><div class="contrib-group fm-author"><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Wang%20CY%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=29263649" class="affpopup" co-rid="_co_idm140188880321424" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Chun-Yang Wang</a>,<span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">1,</span><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">2</span>&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Liu%20S%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=29263649" class="affpopup" co-rid="_co_idm140188880534896" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Shu Liu</a>,<span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">1,</span><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">2</span>&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Xie%20XN%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=29263649" class="affpopup" co-rid="_co_idm140188895234912" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Xiao-Nv Xie</a>,<span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">1,</span><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">2</span>&nbsp;and&nbsp;&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Tan%20ZR%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=29263649" class="affpopup" co-rid="_co_idm140188874061024" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Zhi-Rong Tan</a><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">1,</span><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">2</span></div></div><div class="fm-panel half_rhythm" style="margin: 0.6923em 0px;"><div class="togglers"><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5726373/#" class="pmctoggle" rid="idm140188928170752_ai" style="color: rgb(100, 42, 143);">Author information</a>&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5726373/#" class="pmctoggle" rid="idm140188928170752_cpl" style="color: rgb(100, 42, 143);">Copyright and License information</a>&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pmc/about/disclaimer/" style="color: rgb(100, 42, 143);">Disclaimer</a></div><div class="fm-article-notes fm-panel half_rhythm" style="margin: 0.6923em 0px;"></div></div><div id="pmclinksbox" class="links-box whole_rhythm" style="border: 1px solid rgb(234, 195, 175); background-color: rgb(255, 244, 206); padding: 0.3923em 0.6923em; margin: 1.3846em 0px; border-top-left-radius: 5px; border-top-right-radius: 5px; border-bottom-right-radius: 5px; border-bottom-left-radius: 5px;"><div class="fm-panel">This article has been&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5726373/citedby/" style="color: rgb(100, 42, 143);">cited by</a>&nbsp;other articles in PMC.</div></div></div><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 16px; line-height: 21px;"></div><div id="idm140188889308256" lang="en" class="tsec sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 16px; line-height: 21px;"><div class="goto jig-ncbiinpagenav-goto-container" style="float: right; text-align: right; font-family: arial, helvetica, clean, sans-serif; font-size: 0.86666em !important;"><span role="menubar"><a class="tgt_dark page-toc-label jig-ncbiinpagenav-goto-heading" href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5726373/#" title="Go to other sections in this page" role="menuitem" aria-expanded="false" aria-haspopup="true" style="background-image: url(https://static.pubmed.gov/portal/portal3rc.fcgi/4160049/img/2846531); background-color: transparent; padding-right: 17px; margin-right: 3px; color: rgb(100, 42, 143); background-position: 100% 43.5%; background-repeat: no-repeat no-repeat;">Go to:</a></span></div><h2 class="head no_bottom_margin ui-helper-clearfix" id="idm140188889308256title" style="font-size: 1.125em; line-height: 1.1111em; margin: 1.125em 0px 0px; color: rgb(152, 87, 53); min-height: 0px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(151, 176, 200); font-family: arial, helvetica, clean, sans-serif; font-weight: normal;">Abstract</h2><div><p id="__p1" class="p p-first-last" style="margin-top: 0.6923em; margin-bottom: 0.6923em;"><b><span style="color: rgb(255, 0, 0);">The intestinal peptide transporter 1 (PepT1) was first identified in 1994. It plays a crucial role in the absorption of small peptides including not only &gt;400 different dipeptides and 8,000 tripeptides digested from dietary proteins but also a repertoire of structurally related compounds and drugs</span></b>. <b><span style="color: rgb(0, 85, 255);">Owing to its critical role in the bioavailability of peptide-like drugs, such as the anti-cancer agents and anti-virus drug, PepT1 is increasingly becoming a striking prodrug-designing target</span></b>. Therefore, the understanding of PepT1 gene regulation is of great importance both for dietary adaptation and for clinical drug treatment. After decades of research, it has been recognized that PepT1 could be regulated at the transcriptional and post-transcriptional levels by numerous factors. Therefore, the present review intends to summarize the progress made in the regulation of PepT1 and provide insights into the PepT1’s potential in clinical aspects of nutritional and drug therapies.</p></div><div class="sec" style="clear: both;"><strong class="kwd-title">Keywords:&nbsp;</strong><span class="kwd-text">PepT1, dietary, regulation, transport activity, absorption, bioavailability</span></div><div class="sec" style="clear: both;"><span class="kwd-text"><br></span></div><div class="sec" style="clear: both;"><span class="kwd-text"></span><span class="kwd-text"><p style="text-align: center;"></p><p><br></p><br></span></div></div></div><p></p><p style="text-align: center;"></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/997A80385E4EE5F310" class="txc-image" actualwidth="959" hspace="1" vspace="1" border="0" width="959" exif="{}" data-filename="스크린샷 2020-02-21 오전 5.02.17.png" style="clear:none;float:none;" id="A_997A80385E4EE5F310C73C"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/9980124C5E543DE810" class="txc-image" actualwidth="972" hspace="1" vspace="1" border="0" width="972" exif="{}" data-filename="스크린샷 2020-02-25 오전 6.19.13.png" style="clear:none;float:none;" id="A_9980124C5E543DE8106FE8"/></p><p></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>가. 구강 및 위</b></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질은 구강내에서 분해되지 않음. 저작작용과 침의 혼합으로 기계적으로 해체된 후 위에서 소화되기 시작함. <b><span style="color: rgb(255, 0, 0);">위에서는 단백질 소화효소인 펩신</span></b>이 존재함. <b><span style="color: rgb(0, 85, 255);">펩신은 유문점막(주세포)에서 불활성 형태인 펩시노겐으로 분비</span></b>됨. <b><span style="color: rgb(255, 0, 0);">불활성 펩시노겐은 염산의 작용으로 펩신으로 전환되어 활성</span></b>을 가짐.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(9, 0, 255);">펩신은 단백질 중 특정한 펩티드 결합부분을 가수분해</span></b>함. 즉 <b><span style="color: rgb(9, 0, 255);">글루탐산, 아스파르트산, 시스테인 등 산성 아미노산의 카르복실기와 페닐알라닌 또는 티로신 등 아미노기와의 펩티드 결합을 분해</span></b>함. <b><span style="color: rgb(255, 0, 0);">펩신작용의 최적 pH는 1.5~2이므로 위내에서만 작용</span></b>할 수 있음.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;"><b>Pepsin</b>&nbsp;is an&nbsp;<a href="https://en.wikipedia.org/wiki/Endopeptidase" title="Endopeptidase" style="color: rgb(11, 0, 128); background-image: none;">endopeptidase</a>&nbsp;that breaks down&nbsp;<a href="https://en.wikipedia.org/wiki/Protein" title="Protein" style="color: rgb(11, 0, 128); background-image: none;">proteins</a>&nbsp;into smaller&nbsp;<a href="https://en.wikipedia.org/wiki/Amino_acid" title="Amino acid" style="color: rgb(11, 0, 128); background-image: none;">amino acids</a>. It is produced in the&nbsp;<a href="https://en.wikipedia.org/wiki/Gastric_chief_cell" title="Gastric chief cell" style="color: rgb(11, 0, 128); background-image: none;">chief cells</a>&nbsp;of the stomach lining and is one of the main&nbsp;<a href="https://en.wikipedia.org/wiki/Digestive_enzyme" title="Digestive enzyme" style="color: rgb(11, 0, 128); background-image: none;">digestive enzymes</a>&nbsp;in the&nbsp;<a href="https://en.wikipedia.org/wiki/Digestive_system" class="mw-redirect" title="Digestive system" style="color: rgb(11, 0, 128); background-image: none;">digestive systems</a>&nbsp;of humans and many other animals, where it helps&nbsp;<a href="https://en.wikipedia.org/wiki/Digestion" title="Digestion" style="color: rgb(11, 0, 128); background-image: none;">digest</a>&nbsp;the proteins in&nbsp;<a href="https://en.wikipedia.org/wiki/Food" title="Food" style="color: rgb(11, 0, 128); background-image: none;">food</a>.<b><span style="color: rgb(255, 0, 0);"> Pepsin is an&nbsp;</span><a href="https://en.wikipedia.org/wiki/Aspartic_protease" title="Aspartic protease" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">aspartic protease</span></a><span style="color: rgb(255, 0, 0);">, using a catalytic aspartate in its&nbsp;</span><a href="https://en.wikipedia.org/wiki/Active_site" title="Active site" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">active site</span></a></b>.<sup id="cite_ref-:0_2-0" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Pepsin#cite_note-:0-2" style="color: rgb(11, 0, 128); background-image: none;">[2]</a></sup></p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;">I<b><span style="color: rgb(255, 0, 0);">t is one of two principal proteases in the human digestive system, the other two being&nbsp;</span><a href="https://en.wikipedia.org/wiki/Chymotrypsin" title="Chymotrypsin" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">chymotrypsin</span></a><span style="color: rgb(255, 0, 0);">&nbsp;and&nbsp;</span><a href="https://en.wikipedia.org/wiki/Trypsin" title="Trypsin" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">trypsin</span></a></b>. During the process of digestion, these enzymes, each of which is specialized in severing links between particular types of&nbsp;<a href="https://en.wikipedia.org/wiki/Amino_acid" title="Amino acid" style="color: rgb(11, 0, 128); background-image: none;">amino acids</a>, collaborate to break down dietary proteins into their components, i.e., peptides and amino acids, which can be readily&nbsp;<a href="https://en.wikipedia.org/wiki/Small_intestine#Absorption" title="Small intestine" style="color: rgb(11, 0, 128); background-image: none;">absorbed by the small intestine</a>. <b><span style="color: rgb(255, 0, 0);">Pepsin is most efficient in cleaving&nbsp;</span><a href="https://en.wikipedia.org/wiki/Peptide_bond" title="Peptide bond" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">peptide bonds</span></a><span style="color: rgb(255, 0, 0);">&nbsp;between&nbsp;</span><a href="https://en.wikipedia.org/wiki/Hydrophobe" title="Hydrophobe" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">hydrophobic</span></a><span style="color: rgb(255, 0, 0);">&nbsp;and preferably&nbsp;</span><a href="https://en.wikipedia.org/wiki/Aromaticity" title="Aromaticity" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">aromatic</span></a><span style="color: rgb(255, 0, 0);">&nbsp;amino acids such as&nbsp;</span><a href="https://en.wikipedia.org/wiki/Phenylalanine" title="Phenylalanine" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">phenylalanine</span></a><span style="color: rgb(255, 0, 0);">,&nbsp;</span><a href="https://en.wikipedia.org/wiki/Tryptophan" title="Tryptophan" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">tryptophan</span></a><span style="color: rgb(255, 0, 0);">, and&nbsp;</span><a href="https://en.wikipedia.org/wiki/Tyrosine" title="Tyrosine" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">tyrosine</span></a></b>.<sup id="cite_ref-pmid18429164_3-0" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Pepsin#cite_note-pmid18429164-3" style="color: rgb(11, 0, 128); background-image: none;">[3]</a></sup></p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;"><br></p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/991335335E55A26019" class="txc-image" actualwidth="577" hspace="1" vspace="1" border="0" width="577" exif="{}" data-filename="스크린샷 2020-02-26 오전 7.40.09.png" style="clear:none;float:none;" id="A_991335335E55A26019A99E"/></p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;"><br></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질은 위에서 일부만 소화되며 유미즙의 형태로 유문을 지나 십이지장으로 내려감. 소장내는 알카리성인 췌장액과 담즙이 분비되어서<b><span style="color: rgb(255, 0, 0);"> 유미즙의 pH가 6.5~7.5로 상승하여 펩신의 작용이 중단</span></b>됨. <b><span style="color: rgb(9, 0, 255);">소장에서 각종 protease가 작용하여 아미노산으로 분해 흡수</span></b>됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99A1F3365E4EEB6314" class="txc-image" actualwidth="541" hspace="1" vspace="1" border="0" width="541" exif="{}" data-filename="스크린샷 2020-02-21 오전 5.25.26.png" style="clear:none;float:none;" id="A_99A1F3365E4EEB6314A868"/></p><p><b style="color: rgb(0, 0, 0); font-family: Calibri, sans-serif; font-size: 11pt; line-height: 17.600000381469727px;"><font size="5" color="black" face="Tahoma"><span style="font-size: 12pt; line-height: 25.600000381469727px; font-family: Tahoma, sans-serif; color: rgb(0, 85, 255);">Gastrointestinal pH profile in subjects with irritable bowel syndrome&nbsp;</span></font></b></p><p style="margin: 0cm 0cm 2.85pt; line-height: 17.600000381469727px; font-size: 11pt; font-family: Calibri, sans-serif; color: rgb(0, 0, 0); vertical-align: middle;"><b><font size="2" color="black" face="Tahoma"><span style="font-size: 10.5pt; line-height: 16.799999237060547px; font-family: Tahoma, sans-serif; letter-spacing: -0.1pt;">David Lalezari&nbsp;</span></font></b></p><p style="margin: 0cm 0cm 1cm; line-height: 17.600000381469727px; font-size: 11pt; font-family: Calibri, sans-serif; color: rgb(0, 0, 0); vertical-align: middle;"><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">Cedar Sinai Medical Center, Los Angeles, CA, USA</span></font></p><p class="08correspodence" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal;"><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">Department of Gastroenterology, Cedar Sinai Medical Center,&nbsp;<br>Los Angeles, CA, USA</span></font></p><p class="08correspodence" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal;"><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">Conflict of Interest: None</span></font></p><p class="08correspodence" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal;"><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">Correspondence to: David Lalezari, MD, Department of Medicine, St Mary-UCLA Medical Center, Long Beach, 90802, CA, USA,&nbsp;<br>Tel.: +818 430 4000, Fax: +818 708 8142,&nbsp;<br>e-mail:&nbsp;</span></font><font size="1" face="Tahoma"><span lang="EN-GB" style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">DrDLalezari@hotmail.com</span></font></p><p style="margin: 0cm 0cm 1cm; line-height: 17.600000381469727px; font-size: 11pt; font-family: Calibri, sans-serif; color: rgb(0, 0, 0); vertical-align: middle;"><font size="1" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">Received 23 May 2012; accepted 2 July 2012</span></font></p><p style="margin: 32.05pt 0cm 13.6pt; line-height: 11.4pt; font-size: 11pt; font-family: Calibri, sans-serif; color: rgb(0, 0, 0); text-align: justify; vertical-align: middle;"><b><font size="2" color="black" face="Tahoma"><span style="font-size: 9.5pt; font-family: Tahoma, sans-serif;">Abstract</span></font></b></p><p class="05abstract" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal;"><span class="05abstract1"><b><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">Aim</span></font></b></span><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">&nbsp;To investigate the small bowel pH profile and small intestine transit time (SITT) in healthy controls and patients with irritable bowel syndrome (IBS).&nbsp;</span></font></p><p class="05abstract" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal;"><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;"><br></span></font></p><p class="05abstract" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal;"><span class="05abstract1"><b><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">Methods</span></font></b></span><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">&nbsp;Nine IBS patients (3 males, mean age 35 yr) and 10 healthy subjects (6 males, mean age 33 yr) were studied. Intestinal pH profile and SITT were assessed by a wireless motility pH and pressure capsule (Smart Pill). Mean pH values were measured in the small intestine (SI) and compared both within and between groups. Data presented as mean or median, ANOVA, P &lt;0.05 for significance.&nbsp;</span></font></p><p class="05abstract" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal;"><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;"><br></span></font></p><p class="05abstract" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal;"><span class="05abstract1"><b><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">Results</span></font></b></span><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">&nbsp;We found the pH for the first (Q1), second (Q2), third (Q3), and fourth quartile (Q4) of the SI in healthy versus IBS patients was 5.608 &#65533; 0.491 vs. 5.667 &#65533; 0.297, 6.200 &#65533; 0.328 vs. 6.168 &#65533; 0.288, 6.679 &#65533; 0.316 vs. 6.741 &#65533; 0.322, and 6.884 &#65533; 0.200 vs. 6.899 &#65533; 0.303, respectively. We found no significant group difference in pH per quartile (P=0.7979). The proximal SI was significantly more acidic, compared to distal segments, in both healthy subjects and IBS patients (P&lt;0.0001). We found no significant difference in the measured SITT between IBS and control groups with a mean SITT of 218.56 &#65533; 59.60 min and 199.20 &#65533; 82.31 min, respectively (P=0.55).</span></font></p><p class="05abstract" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal;"><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;"><br></span></font></p><p><span class="05abstract1" style="color: rgb(0, 0, 0); font-family: Times; line-height: normal; font-size: 9pt;"><b><font size="1" color="black" face="Tahoma"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">Conclusion</span></font></b></span><font size="1" face="Tahoma" style="color: rgb(0, 0, 0); line-height: normal;"><span style="font-size: 9pt; line-height: 14.399999618530273px; font-family: Tahoma, sans-serif;">&nbsp;This study shows the <b><span style="color: rgb(255, 0, 0);">presence of a gradient of pH along the SI, in both IBS and healthy subjects, the distal being less acidic. These finding may be of importance in small bowel homeostasis</span></b>.</span></font><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><a href="https://gut.bmj.com/content/gutjnl/29/8/1035.full.pdf" target="_blank" rel="noopener noreferrer" class="tx-link"><img src="https://t1.daumcdn.net/cfile/cafe/99C2944E5E4EECE113" class="txc-image" actualwidth="1024" hspace="1" vspace="1" border="0" width="1024" exif="{}" data-filename="스크린샷 2020-02-21 오전 5.32.02.png" style="clear:none;float:none;" id="A_99C2944E5E4EECE11393CF"/></a></p><p></p><p style="text-align: center;"></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>나. 소장</b></span></p><p><span style="font-size: 15px; line-height: 23px;">위에서 내려온 유미즙 즉 단백질은 소장에서<b><span style="color: rgb(9, 0, 255);"> 췌장액과 소장액에 있는 단백질분해 효소</span></b>에 의해서 아미노산으로 완전히 가수분해됨. <b><span style="color: rgb(255, 0, 0);">유미즙이 소장으로 내려모면 소장벽에서 세크레틴이 분비되어 췌장액 분비를 촉진</span></b>함. <b><span style="color: rgb(9, 0, 255);">소장(십이지장)에서 콜레시스토키닌이 분비되어 이 자극으로 췌장에서 트립시노겐과 키모트립시노겐이 불활성 형태로 분비</span></b>됨. 소장에서 엔테로키나아제가 분비되어&nbsp;트립시노겐은 트립신으로 활성화됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/994EAC345E4EF39C19" class="txc-image" actualwidth="589" hspace="1" vspace="1" border="0" width="589" exif="{}" data-filename="스크린샷 2020-02-21 오전 5.45.54.png" style="clear:none;float:none;" id="A_994EAC345E4EF39C1908B8"/></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/995799345E4EF39C18" class="txc-image" actualwidth="570" hspace="1" vspace="1" border="0" width="570" exif="{}" data-filename="스크린샷 2020-02-21 오전 6.00.34.png" style="clear:none;float:none;" id="A_995799345E4EF39C186D49"/></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99EC96375E4EF3F519" class="txc-image" actualwidth="663" hspace="1" vspace="1" border="0" width="663" exif="{}" data-filename="스크린샷 2020-02-21 오전 6.02.14.png" style="clear:none;float:none;" id="A_99EC96375E4EF3F51983F0"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>단백질 분해효소(protease)</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 키모트립신</b> - <b><span style="color: rgb(255, 0, 0);">벤젠핵을 가진 아미노산(페닐알라닌, 티로신 등)의 카르복실기가 관여하고 있는 펩티드 결합에 작용</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 트립신</b> - 리신 또는 아르기닌(염기성 아미노산)의 카르복실기를 분해함.&nbsp;<b><span style="color: rgb(9, 0, 255);">염기성 아미노산의 카르복실기에 작용</span></b>함. 이러한 효소들의 작용을 받아 단백질은 점차 분해되어 디펩티드로부터 저분자의 펩티드까지 다양한 종류의 펩티드로 분해됨</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><b style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">Trypsin</b><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;(</span><a href="https://en.wikipedia.org/wiki/Enzyme_Commission_number" title="Enzyme Commission number" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">EC</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;</span><a rel="nofollow" class="external text" href="https://enzyme.expasy.org/EC/3.4.21.4" style="color: rgb(102, 51, 102); background-image: linear-gradient(transparent, transparent), url(http://cafe.daum.net/w/skins/Vector/resources/skins.vector.styles/images/external-link-ltr-icon.svg?b4b84); background-attachment: initial, initial; background-origin: initial, initial; background-clip: initial, initial; background-color: rgb(255, 255, 255); background-size: initial, initial; padding-right: 13px; font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: 100% 50%; background-repeat: no-repeat;">3.4.21.4</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">) is a&nbsp;</span><a href="https://en.wikipedia.org/wiki/Serine_protease" title="Serine protease" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">serine protease</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;from the&nbsp;</span><a href="https://en.wikipedia.org/wiki/PA_clan" class="mw-redirect" title="PA clan" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">PA clan</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;superfamily, found in the&nbsp;</span><a href="https://en.wikipedia.org/wiki/Digestive_system" class="mw-redirect" title="Digestive system" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">digestive system</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;of many&nbsp;</span><a href="https://en.wikipedia.org/wiki/Vertebrates" class="mw-redirect" title="Vertebrates" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">vertebrates</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">, where it&nbsp;</span><a href="https://en.wikipedia.org/wiki/Hydrolysis" title="Hydrolysis" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">hydrolyzes</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;</span><a href="https://en.wikipedia.org/wiki/Protein" title="Protein" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">proteins</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">.</span><sup id="cite_ref-pmid7845208_2-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px; color: rgb(34, 34, 34); font-family: sans-serif; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><a href="https://en.wikipedia.org/wiki/Trypsin#cite_note-pmid7845208-2" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[2]</a></sup><sup id="cite_ref-3" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px; color: rgb(34, 34, 34); font-family: sans-serif; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><a href="https://en.wikipedia.org/wiki/Trypsin#cite_note-3" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[3]</a></sup><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;Trypsin is formed in the&nbsp;</span><a href="https://en.wikipedia.org/wiki/Small_intestine" title="Small intestine" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">small intestine</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;when its&nbsp;</span><a href="https://en.wikipedia.org/wiki/Zymogen" title="Zymogen" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">proenzyme</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;form, the&nbsp;</span><a href="https://en.wikipedia.org/wiki/Trypsinogen" title="Trypsinogen" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">trypsinogen</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;produced by the&nbsp;</span><a href="https://en.wikipedia.org/wiki/Pancreas" title="Pancreas" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">pancreas</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">, is activated. <b><span style="color: rgb(9, 0, 255);">Trypsin cleaves</span><span style="color: rgb(9, 0, 255);">&nbsp;</span></b></span><b><a href="https://en.wikipedia.org/wiki/Peptide" title="Peptide" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span style="color: rgb(9, 0, 255);">peptide</span></a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><span style="color: rgb(9, 0, 255);">&nbsp;</span><span style="color: rgb(9, 0, 255);">chains mainly at the</span><span style="color: rgb(9, 0, 255);">&nbsp;</span></span><a href="https://en.wikipedia.org/wiki/Carboxyl" class="mw-redirect" title="Carboxyl" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span style="color: rgb(9, 0, 255);">carboxyl</span></a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><span style="color: rgb(9, 0, 255);">&nbsp;</span><span style="color: rgb(9, 0, 255);">side of the</span><span style="color: rgb(9, 0, 255);">&nbsp;</span></span><a href="https://en.wikipedia.org/wiki/Amino_acids" class="mw-redirect" title="Amino acids" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span style="color: rgb(9, 0, 255);">amino acids</span></a><span style="color: rgb(9, 0, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;</span><a href="https://en.wikipedia.org/wiki/Lysine" title="Lysine" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span style="color: rgb(9, 0, 255);">lysine</span></a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><span style="color: rgb(9, 0, 255);">&nbsp;</span><span style="color: rgb(9, 0, 255);">or</span><span style="color: rgb(9, 0, 255);">&nbsp;</span></span><a href="https://en.wikipedia.org/wiki/Arginine" title="Arginine" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span style="color: rgb(9, 0, 255);">arginine</span></a><span style="color: rgb(9, 0, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">.</span></b><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 카르복시펩티다아제</b> - <b><span style="color: rgb(255, 0, 0);">카르복실기가 말단을 이루는 끝부분에 작용하여 펩티드 결합을 끊어냄</span></b>.</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">#&nbsp;<b><span style="color: rgb(9, 0, 255);">아미노펩티다아제 -&nbsp;카르복실기 대신에 아미노기가 말달을 이루는 끝부분에 작용</span></b>함. 이러한 효소들에 의해 연쇄의 끝부분으로부터 끊어내어 디펩티드만 남음</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">A&nbsp;</span><b style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">carboxypeptidase</b><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;(</span><a href="https://en.wikipedia.org/wiki/Enzyme_Commission_number" title="Enzyme Commission number" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">EC number</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;3.4.16 - 3.4.18) is a&nbsp;</span><a href="https://en.wikipedia.org/wiki/Protease" title="Protease" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">protease</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;</span><a href="https://en.wikipedia.org/wiki/Enzyme" title="Enzyme" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">enzyme</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;that&nbsp;</span><a href="https://en.wikipedia.org/wiki/Hydrolysis" title="Hydrolysis" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">hydrolyzes</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;(cleaves) a&nbsp;</span><a href="https://en.wikipedia.org/wiki/Peptide_bond" title="Peptide bond" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">peptide bond</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;at the carboxy-terminal (C-terminal) end of a&nbsp;</span><a href="https://en.wikipedia.org/wiki/Protein" title="Protein" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">protein</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;or&nbsp;</span><a href="https://en.wikipedia.org/wiki/Peptide" title="Peptide" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">peptide</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">. This is in contrast to an&nbsp;</span><a href="https://en.wikipedia.org/wiki/Aminopeptidase" title="Aminopeptidase" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">aminopeptidases</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">, which cleave peptide bonds at the N-terminus of proteins. Humans, animals, bacteria and plants contain several types of carboxypeptidases that have diverse functions ranging from catabolism to protein maturation.</span><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><b style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">Aminopeptidases</b><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;are&nbsp;</span><a href="https://en.wikipedia.org/wiki/Enzyme" title="Enzyme" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">enzymes</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;that&nbsp;</span><a href="https://en.wikipedia.org/wiki/Catalysis" title="Catalysis" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">catalyze</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;the cleavage of&nbsp;</span><a href="https://en.wikipedia.org/wiki/Amino_acid" title="Amino acid" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">amino acids</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;from the amino terminus (N-terminus) of&nbsp;</span><a href="https://en.wikipedia.org/wiki/Protein" title="Protein" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">proteins</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;or&nbsp;</span><a href="https://en.wikipedia.org/wiki/Peptide" title="Peptide" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">peptides</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;(exopeptidases).They are widely distributed throughout the animal and plant kingdoms and are found in many subcellular&nbsp;</span><a href="https://en.wikipedia.org/wiki/Organelle" title="Organelle" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">organelles</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">, in&nbsp;</span><a href="https://en.wikipedia.org/wiki/Cytosol" title="Cytosol" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">cytosol</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">, and as&nbsp;</span><a href="https://en.wikipedia.org/wiki/Cell_membrane" title="Cell membrane" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">membrane</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">&nbsp;components. Aminopeptidases are used in essential cellular functions. Many, but not all, of these peptidases are zinc&nbsp;</span><a href="https://en.wikipedia.org/wiki/Metalloprotein#Metalloenzymes" title="Metalloprotein" style="color: rgb(11, 0, 128); background-image: none; background-color: rgb(255, 255, 255); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-position: initial initial; background-repeat: initial initial;">metalloenzymes</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">.</span><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 디펩티다아제</b> - <b><span style="color: rgb(255, 0, 0);">디펩티드를 아미노산으로 분해</span></b>함. 일부 펩티드는 흡수되어 소장벽내에서 아미노산으로 분해되기도 함.&nbsp;</span></p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><b>Dipeptidases</b>&nbsp;are&nbsp;<a href="https://en.wikipedia.org/wiki/Enzyme" title="Enzyme" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">enzymes</a>&nbsp;secreted by&nbsp;<a href="https://en.wikipedia.org/wiki/Enterocyte" title="Enterocyte" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">enterocytes</a>&nbsp;into the&nbsp;<a href="https://en.wikipedia.org/wiki/Small_intestine" title="Small intestine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">small intestine</a>. Dipeptidases hydrolyze bound pairs of&nbsp;<a href="https://en.wikipedia.org/wiki/Amino_acid" title="Amino acid" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">amino acids</a>, called&nbsp;<a href="https://en.wikipedia.org/wiki/Dipeptide" title="Dipeptide" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">dipeptides</a>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">Dipeptidases are secreted onto the&nbsp;<a href="https://en.wikipedia.org/wiki/Brush_border" title="Brush border" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">brush border</a>&nbsp;of the villi in the small intestine, where they cleave dipeptides into their two component amino acids prior to absorption.</p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><table class="txc-table" width="700" cellspacing="0" cellpadding="0" border="0" style="border:none;border-collapse:collapse;;font-family:gulim;font-size:12px"><tbody><tr><td style="width: 55px; height: 24px; border: 1px solid rgb(204, 204, 204);"><p><b><span style="font-size: 11pt;">기</span><span style="font-size: 11pt;">관&nbsp;</span></b></p></td><td style="width: 156px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-top-width: 1px; border-top-style: solid; border-top-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;"><b>비활성 전구체&nbsp;</b></span></p></td><td style="width: 106px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-top-width: 1px; border-top-style: solid; border-top-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;"><b>활성 촉진물질&nbsp;</b></span></p></td><td style="width: 128px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-top-width: 1px; border-top-style: solid; border-top-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;"><b>활성효소&nbsp;</b></span></p></td><td style="width: 254px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-top-width: 1px; border-top-style: solid; border-top-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;"><b>소화작용&nbsp;</b></span></p></td></tr><tr><td style="width: 55px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-left-width: 1px; border-left-style: solid; border-left-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">위&nbsp;</span></p></td><td style="width: 156px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">펩시노겐</span></p></td><td style="width: 106px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;위산</span></p></td><td style="width: 128px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;펩신</span></p><p><span style="font-size: 11pt;">레닌(유아에서)</span></p></td><td style="width: 254px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">단백질 - 펩톤</span></p><p><span style="font-size: 11pt;">카세인 - 응유&nbsp;</span></p></td></tr><tr><td style="width: 55px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-left-width: 1px; border-left-style: solid; border-left-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">췌장&nbsp;</span></p></td><td style="width: 156px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">트립시노겐</span></p></td><td style="width: 106px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">엔테로키나아제&nbsp;</span></p></td><td style="width: 128px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">트립신&nbsp;</span></p></td><td style="width: 254px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">펩톤 내부의 알라닌, 라이신 -&gt; 폴리펩티드, 디펩티드&nbsp;</span></p></td></tr><tr><td style="width: 55px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-left-width: 1px; border-left-style: solid; border-left-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;</span></p></td><td style="width: 156px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">키모트립시노겐&nbsp;</span></p></td><td style="width: 106px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">활성 트립신&nbsp;</span></p></td><td style="width: 128px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">키모트립신&nbsp;</span></p></td><td style="width: 254px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">펩톤 내부의 Tyr, TrP -&gt;폴리펩티드, 디펩티드</span></p></td></tr><tr><td style="width: 55px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-left-width: 1px; border-left-style: solid; border-left-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;</span></p></td><td style="width: 156px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">프로카르복시펩티다제&nbsp;</span></p></td><td style="width: 106px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">활성 트립신&nbsp;</span></p></td><td style="width: 128px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">카르복시펩티다제&nbsp;</span></p></td><td style="width: 254px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">카르복시말단 -&gt; 디펩티드, 아미노산&nbsp;</span></p></td></tr><tr><td style="width: 55px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-left-width: 1px; border-left-style: solid; border-left-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;</span></p></td><td style="width: 156px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;</span></p></td><td style="width: 106px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;</span></p></td><td style="width: 128px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">아미노펩티다제 &nbsp;</span></p></td><td style="width: 254px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">아미노말단 -&gt; 펩티드, 디펩티드, 아미노산&nbsp;</span></p></td></tr><tr><td style="width: 55px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-left-width: 1px; border-left-style: solid; border-left-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">소장&nbsp;</span></p></td><td style="width: 156px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;</span></p></td><td style="width: 106px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;</span></p></td><td style="width: 128px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">디펩티다제</span></p></td><td style="width: 254px; height: 24px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;">&nbsp;디펩티드 -&gt; 아미노산</span></p></td></tr></tbody></table><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>2) 흡수 및 운반</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">단백질의 소화산물인 아미노산과 디펩티드는 소장상부에서 흡수</span></b>함. 소장 전막세포는 융모를 형성하고 있으며 아미노산은 <b><span style="color: rgb(9, 0, 255);">확산이나 에너지를 필요로 하는 능동수송을 통해 융모벽을 통과</span></b>함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">주의) <b><span style="color: rgb(255, 0, 0);">아미노산들이 능동수송 체계를 이용할때 유사구조를 가진 아미노산들이 같은 체계를 공유하게 되므로 특정 아미노산이 과다하게 많은 경우 다른 아미노산이 적게 흡수</span></b>될 수 있음. 예를들어<b><span style="color: rgb(0, 85, 255);"> 다량의 아르기닌을 보충제로 복용하면 리신의 흡수가 저해될 수 있</span></b>음.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">흡수된 아미노산은 모세혈관으로 운반되고 간문맥을 통해 간으로 이동하여 근육합성 또는 당신생에 활용됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99B36B455E4EF72319" class="txc-image" actualwidth="336" hspace="1" vspace="1" border="0" width="336" exif="{}" data-filename="스크린샷 2020-02-21 오전 6.15.54.png" style="clear:none;float:none;" id="A_99B36B455E4EF72319D443"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>특이체질과 알레르기</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(9, 0, 255);">특이체질을 가진 사람의 경우 특정 단백질이 아미노산으로 분해되지 않은 채로 소화관을 통과</span></b>할 수 있음. 이 <b><span style="color: rgb(255, 0, 0);">특정 단백질이 장벽을 통과하면 체내에서는 항체를 생성함. 후에 같은 단백질이 또 흡수되면 방어기능으로 알레르기 현상</span></b>이 나타남. 특히&nbsp;<b><span style="color: rgb(9, 0, 255);">유아의 위장관은 미성숙한 상태이므로 큰 분자인 폴리펩티드를 그대로 흡수해서 알레르기 반응</span></b>을 흔히 일으킴.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><h2 class="js-accordion__header" style="font-size: 1.64286em; line-height: 1.30435em; margin: 0px auto 0.52174em; font-weight: 500; color: rgb(38, 119, 139); font-family: rubrik, Arial, sans-serif; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">What are IgE-mediated food allergies?</h2><div class="js-accordion__panel" style="color: rgb(102, 85, 70); font-family: rubrik, Arial, sans-serif; font-size: 17.6px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><p style="font-family: Georgia, 'Times New Roman', 'DejaVu Serif', serif; margin-bottom: 0.85714em;"><b><span style="color: rgb(255, 0, 0);">IgE-mediated food allergies </span></b>cause your child’s immune system to react abnormally when exposed to one or more specific foods such as milk, egg, wheat or nuts. Children with this type of food allergy will react quickly &#8212;&nbsp;<b><span style="color: rgb(9, 0, 255);">within a few minutes to a few hours</span></b>. Immediate reactions are caused by an allergen-specific immunoglobulin E (IgE) antibody that floats around in the blood stream.</p><p style="font-family: Georgia, 'Times New Roman', 'DejaVu Serif', serif; margin-bottom: 0.85714em;">The most common food allergens include:</p><ul style="margin-top: 0.85714em; margin-right: 0px; margin-bottom: 0.85714em; padding: 0px 0px 0px 1.25em; font-family: Georgia, 'Times New Roman', 'DejaVu Serif', serif;"><li>Milk</li><li>Egg</li><li>Soy</li><li>Wheat</li><li>Peanut</li><li>Tree nuts</li><li>Fish</li><li>Shellfish</li></ul><p style="font-family: Georgia, 'Times New Roman', 'DejaVu Serif', serif; margin-bottom: 0.85714em;">All of these foods can trigger&nbsp;<a href="https://www.chop.edu/conditions-diseases/anaphylaxis" style="color: rgb(51, 160, 187); transition: all 0.15s ease-out 0s; -webkit-transition: all 0.15s ease-out 0s; box-shadow: rgb(210, 227, 232) 0px -1px inset;">anaphylaxis</a>&nbsp;(a severe, whole-body allergic reaction) in patients who are allergic.</p><h2 class="js-accordion__header" style="font-size: 1.64286em; line-height: 1.30435em; margin: 0px auto 0.52174em; font-weight: 500; color: rgb(38, 119, 139);">Signs and symptoms of&nbsp;IgE-mediated food allergies</h2><div class="js-accordion__panel" style="font-size: 17.6px;"><p style="font-family: Georgia, 'Times New Roman', 'DejaVu Serif', serif; margin-bottom: 0.85714em;">When your child has a food allergy, her body’s IgE antibodies identify that specific food as an invader and can produce symptoms in multiple areas of the body, including:</p><ul style="margin-top: 0.85714em; margin-right: 0px; margin-bottom: 0.85714em; padding: 0px 0px 0px 1.25em; font-family: Georgia, 'Times New Roman', 'DejaVu Serif', serif;"><li><span style="font-weight: 700;">Skin:</span>&nbsp;“hives” (red blotches or welts that itch), mild to severe swelling</li><li><span style="font-weight: 700;">Eyes:</span>&nbsp;tearing, redness, itch</li><li><span style="font-weight: 700;">Nose:</span>&nbsp;clear discharge, itch, congestion</li><li><span style="font-weight: 700;">Mouth:</span>&nbsp;itch, lip swelling, tongue swelling</li><li><span style="font-weight: 700;">Throat:</span>&nbsp;tightness, trouble speaking, trouble inhaling</li><li><span style="font-weight: 700;">Lungs:</span>&nbsp;shortness of breath, rapid breathing, cough, wheeze</li><li><span style="font-weight: 700;">Stomach:</span>&nbsp;repeated vomiting, nausea, abdominal pain, diarrhea (usually later)</li><li><span style="font-weight: 700;">Heart and circulation:</span>&nbsp;weak pulse, loss of consciousness</li><li><span style="font-weight: 700;">Brain:&nbsp;</span>anxiety, agitation, loss of consciousness</li></ul></div><p style="font-family: Georgia, 'Times New Roman', 'DejaVu Serif', serif; margin-bottom: 0.85714em;"></p><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: &quot;Times New Roman&quot;, stixgeneral, serif; font-size: 15.9991px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial;"></div><div id="idm139791129729376" lang="en" class="tsec sec" style="clear: both; display: none; color: rgb(0, 0, 0); font-family: &quot;Times New Roman&quot;, stixgeneral, serif; font-size: 15.9991px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial;"><div class="goto jig-ncbiinpagenav-goto-container" style="float: right; text-align: right; font-family: arial, helvetica, clean, sans-serif; font-size: 0.86666em !important;"><span role="menubar"><a class="tgt_dark page-toc-label jig-ncbiinpagenav-goto-heading" href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5004213/#" title="Go to other sections in this page" role="menuitem" aria-expanded="false" aria-haspopup="true" style="background: url(&quot;//static.pubmed.gov/portal/portal3rc.fcgi/4160049/img/2846531&quot;) 100% 43.5% no-repeat transparent; padding-right: 17px; margin-right: 3px; text-decoration: none; color: rgb(100, 42, 143);">Go to:</a></span></div><h2 class="head no_bottom_margin ui-helper-clearfix" id="idm139791129729376title" style="font-size: 1.125em; line-height: 1.1111em; margin: 1.125em 0px 0px; color: rgb(152, 87, 53); min-height: 0px; display: block; border-bottom: 1px solid rgb(151, 176, 200); font-family: arial, helvetica, clean, sans-serif; font-weight: normal;">Abstract</h2><div><p id="__p1" class="p p-first-last" style="margin: 0.6923em 0px;">This paper presents current views on the role of immunoglobulin G (IgG) antibodies in the reactions with food antigens in the digestive tract and their role in the diagnosis of food allergy based on the assays of specific IgG class antibodies, with a special focus on contemporary practice guidelines. In the light of current scientific knowledge, the IgG-specific antibody-mediated reactions are a body's natural and normal defensive reactions to infiltrating food antigens, which are considered as pathogens. On the other hand, specific IgG antibodies against food allergens play a crucial role in the induction and maintaining of immunological tolerance to food antigens. The statements of many scientific societies stress that sIgG are of no significant importance in the diagnosis of food allergy since their presence is associated with a normal immune response to food allergens and attests to a protracted exposure to food antigens.</p></div><div class="sec" style="clear: both;"><strong class="kwd-title" style="font-weight: bold;">Keywords:<span>&nbsp;</span></strong><span class="kwd-text"></span></div></div><p></p><div class="fm-sec half_rhythm no_top_margin" style="margin: 0px 0px 0.6923em; font: 400 0.8425em / 1.6363em arial, helvetica, clean, sans-serif; color: rgb(0, 0, 0); letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial;"><h1 class="content-title" style="font-size: 1.5384em; margin: 1em 0px 0.5em; line-height: 1.35em; color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif; font-weight: normal;">Role of immunoglobulin G antibodies in diagnosis of food allergy</h1><div class="half_rhythm" style="margin: 0.6923em 0px;"><div class="contrib-group fm-author"><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Gocki%20J%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=27605894" style="color: rgb(100, 42, 143);">Jacek Gocki</a><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;"><img src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fwww.ncbi.nlm.nih.gov%2Fcorehtml%2Fpmc%2Fpmcgifs%2Fcorrauth.gif" alt="corresponding author" style="max-width: 100%; border: 0px;"></sup><span>&nbsp;</span>and<span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Bartuzi%20Z%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=27605894" style="color: rgb(100, 42, 143);">Zbigniew Bartuzi</a></div></div><div class="fm-panel half_rhythm" style="margin: 0.6923em 0px;"><div class="togglers"><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5004213/#" class="pmctoggle" rid="idm139791127706720_ai" style="text-decoration: none; color: rgb(100, 42, 143);">Author information</a><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5004213/#" class="pmctoggle" rid="idm139791127706720_an" style="text-decoration: none; color: rgb(100, 42, 143);">Article notes</a><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5004213/#" class="pmctoggle" rid="idm139791127706720_cpl" style="text-decoration: none; color: rgb(100, 42, 143);">Copyright and License information</a><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/about/disclaimer/" style="color: rgb(100, 42, 143);">Disclaimer</a></div></div><div id="pmclinksbox" class="links-box whole_rhythm" style="border: 1px solid rgb(234, 195, 175); background-color: rgb(255, 244, 206); padding: 0.3923em 0.6923em; margin: 1.3846em 0px; border-radius: 5px;"><div class="fm-panel"><div>This article has been<span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5004213/citedby/" style="color: rgb(100, 42, 143);">cited by</a><span>&nbsp;</span>other articles in PMC.</div></div></div></div></div><h2 class="head no_bottom_margin ui-helper-clearfix" id="idm139791129729376title" style="font-size: 1.125em; line-height: 1.1111em; margin: 1.125em 0px 0px; color: rgb(152, 87, 53); min-height: 0px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(151, 176, 200); font-family: arial, helvetica, clean, sans-serif; font-weight: normal; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);">Abstract</h2><div style="color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 15.9991px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><p id="__p1" class="p p-first-last" style="margin-top: 0.6923em; margin-bottom: 0.6923em;">This paper presents current views on the role of immunoglobulin G (IgG) antibodies in the reactions with food antigens in the digestive tract and their role in the diagnosis of food allergy based on the assays of specific IgG class antibodies, with a special focus on contemporary practice guidelines.<b><span style="color: rgb(255, 0, 0);"> In the light of current scientific knowledge, the IgG-specific antibody-mediated reactions are a body's natural and normal defensive reactions to infiltrating food antigens, which are considered as pathogens. </span></b>On the other hand, specific IgG antibodies against food allergens play a crucial role in the induction and maintaining of immunological tolerance to food antigens. <b><span style="color: rgb(9, 0, 255);">The statements of many scientific societies stress that sIgG are of no significant importance in the diagnosis of food allergy since their presence is associated with a normal immune response to food allergens and attests to a protracted exposure to food antigens.</span></b></p></div><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 15.9991px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><strong class="kwd-title">Keywords:&nbsp;</strong><span class="kwd-text">immunoglobulin G, food allergy, diagnosis</span></div><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 15.9991px; orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><span class="kwd-text"><br></span></div><p><span style="font-size: 15px; line-height: 23px;"><b>5. 단백질과 아미노산의 대사</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>1) 단백질 대사</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">단백질 대사는 체내에서 고유의 작용을 수행하기 위하여 아미노산 총량을 유지하며 이를 위해서 단백질 합성과 분해가 계속 일어남</span></b>. 지방과 포도당은 잉여물질로 남으면 에너지로 저장하지만 단백질이 잉여로 남으면 체외로 배출됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>체내단백질 요약</b></span></p><p><span style="font-size: 15px; line-height: 23px;">단백질 대사가 활발하게 이루어지는 조직은 혈장, 췌장, 간, 신장, 근육 등임. 체내의 아미노산은 식품 단백질이 소화흡수되어 생성된 아미노산과 그리고<b><span style="color: rgb(0, 85, 255);"> 체조직의 분해로 생성되거나 체내에서 합성된 아미노산들임. 이러한 아미노산들과 간과 각 조직내의 아미노산 총량을 이룸</span></b>.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">아미노산은 필요에 따라 체조직 단백질, 효소와 호르몬, 생리활성물질, 체지방을 합성하거나 에너지를 공급하는 등 다양하게 이용</span></b>됨. 아미노산 분해로 생성된 탄소골격은 시트르산 회로로 들어가 에너지를 발생시킴. 이때 암모니아는 또 다른 아미노산 합성에 쓰이거나 요소로 합성됨.</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">외부 단백질 하루 70g</span></p><p><span style="font-size: 15px; line-height: 23px;">내인성 급원 단백질 하루 140g</span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(9, 0, 255);">과잉 아미노산 하루 0.9~10g 배설</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99DC9B395E4F0E5421" class="txc-image" actualwidth="309" hspace="1" vspace="1" border="0" width="309" exif="{}" data-filename="스크린샷 2020-02-21 오전 7.54.51.png" style="clear:none;float:none;" id="A_99DC9B395E4F0E542119ED"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>2) 아미노산 분해</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>가. 탈아미노 반응(deamination)</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">단백질이 에너지를 발생하기 위해서는 먼저 아미노산에서 아미노기가 떨어져 나가는 탈아미노반응(deamination)이 일어나야</span></b> 함. 그 결과 생성된 아미노기는 다른 물질로 이전되며 이를 <b><span style="color: rgb(0, 85, 255);">아미노기 전이반응(transamination)</span></b>이라고 함. 글루탐산탈수소효소에 의해서 탈아미노반응이 일어나 알파-케토글루타르산이 됨. 이때 NAD+ 조효소가 작용해야 함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/996AF6355E52FD8619" class="txc-image" actualwidth="524" hspace="1" vspace="1" border="0" width="524" exif="{}" data-filename="스크린샷 2020-02-24 오전 7.32.16.png" style="clear:none;float:none;" id="A_996AF6355E52FD86193661"/></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(0, 85, 255);">탈아미노반응(deamination)으로 생성된 아미노산의 탄소골격은 <span style="color: rgb(255, 0, 0);">탄수화물이나 지질이 분해되는 대사경로에 합류하여 시트르산 회로로 들어가 산화과정을 거쳐 에너지를 발생</span></span></b>함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99DFA93F5E55B06D1F" class="txc-image" actualwidth="887" hspace="1" vspace="1" border="0" width="887" exif="{}" data-filename="스크린샷 2020-02-26 오전 8.39.35.png" style="clear:none;float:none;" id="A_99DFA93F5E55B06D1FA854"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">&nbsp;참고)&nbsp;</span><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">The&nbsp;</span><b style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;">urea cycle</b><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;(also known as the&nbsp;</span><b style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;">ornithine cycle</b><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">) is a cycle of&nbsp;</span><a href="https://en.wikipedia.org/wiki/Biochemistry" title="Biochemistry" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">biochemical</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;reactions that produces&nbsp;</span><a href="https://en.wikipedia.org/wiki/Urea" title="Urea" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">urea</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;(NH</span><sub style="line-height: 1; font-size: 11px; color: rgb(34, 34, 34); font-family: sans-serif;">2</sub><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">)</span><sub style="line-height: 1; font-size: 11px; color: rgb(34, 34, 34); font-family: sans-serif;">2</sub><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">CO from&nbsp;</span><a href="https://en.wikipedia.org/wiki/Ammonia" title="Ammonia" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">ammonia</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;(NH</span><sub style="line-height: 1; font-size: 11px; color: rgb(34, 34, 34); font-family: sans-serif;">3</sub><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">). This cycle occurs in&nbsp;</span><a href="https://en.wikipedia.org/wiki/Ureotelic" class="mw-redirect" title="Ureotelic" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">ureotelic</a>-<span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">organisms. The urea cycle converts highly toxic ammonia to urea for excretion.</span><sup id="cite_ref-:0_1-0" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px; color: rgb(34, 34, 34); font-family: sans-serif;"><a href="https://en.wikipedia.org/wiki/Urea_cycle#cite_note-:0-1" style="color: rgb(11, 0, 128); background-image: none;">[1]</a></sup><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;This cycle was the first metabolic cycle to be discovered (</span><a href="https://en.wikipedia.org/wiki/Hans_Adolf_Krebs" title="Hans Adolf Krebs" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">Hans Krebs</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;and&nbsp;</span><a href="https://en.wikipedia.org/wiki/Kurt_Henseleit" title="Kurt Henseleit" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">Kurt Henseleit</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">, 1932), five years before the discovery of the&nbsp;</span><a href="https://en.wikipedia.org/wiki/TCA_cycle" class="mw-redirect" title="TCA cycle" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">TCA cycle</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">. This cycle was described in more detail later on by Ratner and Cohen. The urea cycle takes place primarily in the&nbsp;</span><a href="https://en.wikipedia.org/wiki/Liver" title="Liver" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">liver</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">&nbsp;and, to a lesser extent, in the&nbsp;</span><a href="https://en.wikipedia.org/wiki/Kidney" title="Kidney" style="color: rgb(11, 0, 128); background-image: none; font-family: sans-serif; font-size: 14px; line-height: 22px;">kidneys</a><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);">.</span></p><p><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99CC29335E5445E813" class="txc-image" actualwidth="500" hspace="1" vspace="1" border="0" width="500" exif="{}" data-filename="스크린샷 2020-02-25 오전 6.53.22.png" style="clear:none;float:none;" id="A_99CC29335E5445E813C1BE"/></p><p><span style="color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px; background-color: rgb(255, 255, 255);"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>나. 아미노기 전이반응(transamination)</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">아미노기 전이반응은 비타민 B6가 조효소로 필요한 효소에 의해서 아미노기가 케토산에 전이되는 반응</span></b>임. 대부분 <b><span style="color: rgb(0, 85, 255);">천연에 존재하는 아미노산의 아미노기들은 전이반응 과정을 거쳐 새로운 아미노산을 형성</span></b>함. 예로서 <b><span style="color: rgb(255, 0, 0);">아스파르트산(아미노산)에서 알파-케토글루타르산으로 아미노기가 전이되어 옥살로아세트산과 글루탐산(아미노산)을 합성</span></b>함. 이때 아미노기 전이효소가 아미노기를 전달하는 작용을 함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">참고)&nbsp;</span><span style="font-size: 16px; background-color: rgb(255, 255, 255); color: rgb(34, 34, 34); font-family: AppleSDGothicNeo-Regular, &quot;Malgun Gothic&quot;, &quot;맑은 고딕&quot;, system-ui, -apple-system, Helvetica, sans-serif;"><b><span style="color: rgb(102, 0, 255);">비타민 b6&nbsp; 피리독신 반감기 25-33일(15-22일)</span></b></span></p><div class="r" style="font-size: 10pt; line-height: 1.57; font-family: AppleSDGothicNeo-Regular, &quot;Malgun Gothic&quot;, &quot;맑은 고딕&quot;, system-ui, -apple-system, Helvetica, sans-serif; -webkit-font-smoothing: antialiased; color: rgb(34, 34, 34); background-color: rgb(255, 255, 255); margin: 0px;"><span style="font-size: 16px;">Eighty to ninety percent of&nbsp;</span><b style="font-size: 16px;">vitamin B6</b><span style="font-size: 16px;">&nbsp;in the body is found in muscles and estimated body stores amount to about 170 mg with a&nbsp;</span><b style="font-size: 16px;">half</b><span style="font-size: 16px;">-</span><b style="font-size: 16px;">life</b><span style="font-size: 16px;">&nbsp;of 25-33 days</span><br></div><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99738D365E5446D411" class="txc-image" actualwidth="339" hspace="1" vspace="1" border="0" width="339" exif="{}" data-filename="스크린샷 2020-02-25 오전 6.57.15.png" style="clear:none;float:none;" id="A_99738D365E5446D4111178"/></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99EB814B5E8EEFE531" class="txc-image" actualwidth="522" hspace="1" vspace="1" border="0" width="522" exif="{}" data-filename="스크린샷 2020-04-09 오후 6.49.59.png" style="clear:none;float:none;" id="A_99EB814B5E8EEFE5315F3B"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>다. 탈탄산반응(decarboxylation)</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">탈탄산반응은 아미노산이 비타민 B6를 조효소로 하는 탈탄산효소에 의해 탄산가스를 분리하여 아민이 생성되는 과정</span></b>임. 생성된 <b><span style="color: rgb(0, 85, 255);">아민은 도파민, 세로토닌, 카다베린, 가마-이미노부티르산(GABA)등으로 체내에서 유용하게 이용</span></b>되며 일부 아민은 알레르기 반응을 일으키기도 함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;"><b><span style="color: rgb(255, 0, 0);">Glutamate decarboxylase</span><span style="color: rgb(255, 0, 0);">&nbsp;or&nbsp;</span><span style="color: rgb(255, 0, 0);">glutamic acid decarboxylase</span><span style="color: rgb(255, 0, 0);">&nbsp;(</span><span style="color: rgb(255, 0, 0);">GAD</span><span style="color: rgb(255, 0, 0);">) is an&nbsp;</span><a href="https://en.wikipedia.org/wiki/Enzyme" title="Enzyme" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">enzyme</span></a><span style="color: rgb(255, 0, 0);">&nbsp;that catalyzes the decarboxylation of&nbsp;</span><a href="https://en.wikipedia.org/wiki/Glutamate" class="mw-redirect" title="Glutamate" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">glutamate</span></a><span style="color: rgb(255, 0, 0);">&nbsp;to&nbsp;</span><a href="https://en.wikipedia.org/wiki/GABA" class="mw-redirect" title="GABA" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">GABA</span></a><span style="color: rgb(255, 0, 0);">&nbsp;and CO</span><sub style="line-height: 1; font-size: 11px;"><span style="color: rgb(255, 0, 0);">2</span></sub><span style="color: rgb(255, 0, 0);">. GAD uses&nbsp;</span><a href="https://en.wikipedia.org/wiki/Pyridoxal-phosphate" class="mw-redirect" title="Pyridoxal-phosphate" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">PLP</span></a><span style="color: rgb(255, 0, 0);">&nbsp;as a&nbsp;</span><a href="https://en.wikipedia.org/wiki/Cofactor_(biochemistry)" title="Cofactor (biochemistry)" style="color: rgb(11, 0, 128); background-image: none;"><span style="color: rgb(255, 0, 0);">cofactor</span></a><span style="color: rgb(255, 0, 0);">.</span></b> The reaction proceeds as follows:</p><dl style="margin-top: 0.2em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;"><dd style="margin-left: 1.6em; margin-bottom: 0.1em; margin-right: 0px;">HOOC-CH<sub style="line-height: 1; font-size: 11px;">2</sub>-CH<sub style="line-height: 1; font-size: 11px;">2</sub>-CH(NH<sub style="line-height: 1; font-size: 11px;">2</sub>)-COOH → CO<sub style="line-height: 1; font-size: 11px;">2</sub>&nbsp;+ HOOC-CH<sub style="line-height: 1; font-size: 11px;">2</sub>-CH<sub style="line-height: 1; font-size: 11px;">2</sub>-CH<sub style="line-height: 1; font-size: 11px;">2</sub>NH<sub style="line-height: 1; font-size: 11px;">2</sub></dd></dl><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; line-height: 22px;">In mammals, GAD exists in two&nbsp;<a href="https://en.wikipedia.org/wiki/Isoform" class="mw-redirect" title="Isoform" style="color: rgb(11, 0, 128); background-image: none;">isoforms</a>&nbsp;with molecular weights of 67 and 65 kDa (GAD<sub style="line-height: 1; font-size: 11px;">67</sub>&nbsp;and GAD<sub style="line-height: 1; font-size: 11px;">65</sub>), which are encoded by two different&nbsp;<a href="https://en.wikipedia.org/wiki/Gene" title="Gene" style="color: rgb(11, 0, 128); background-image: none;">genes</a>&nbsp;on different&nbsp;<a href="https://en.wikipedia.org/wiki/Chromosome" title="Chromosome" style="color: rgb(11, 0, 128); background-image: none;">chromosomes</a>&nbsp;(<a href="https://en.wikipedia.org/wiki/GAD1" title="GAD1" style="color: rgb(11, 0, 128); background-image: none;">GAD1</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/GAD2" title="GAD2" style="color: rgb(11, 0, 128); background-image: none;">GAD2</a>&nbsp;genes, chromosomes 4 and 10 respectively).<sup id="cite_ref-pmid2069816_1-0" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-pmid2069816-1" style="color: rgb(11, 0, 128); background-image: none;">[1]</a></sup><sup id="cite_ref-ReferenceA_2-0" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-ReferenceA-2" style="color: rgb(11, 0, 128); background-image: none;">[2]</a></sup>&nbsp;GAD<sub style="line-height: 1; font-size: 11px;">67</sub>&nbsp;and GAD<sub style="line-height: 1; font-size: 11px;">65</sub>&nbsp;are expressed in the brain where GABA is used as a&nbsp;<a href="https://en.wikipedia.org/wiki/Neurotransmitter" title="Neurotransmitter" style="color: rgb(11, 0, 128); background-image: none;">neurotransmitter</a>, and they are also expressed in the&nbsp;<a href="https://en.wikipedia.org/wiki/Insulin" title="Insulin" style="color: rgb(11, 0, 128); background-image: none;">insulin</a>-producing&nbsp;<a href="https://en.wikipedia.org/wiki/Beta_cell" title="Beta cell" style="color: rgb(11, 0, 128); background-image: none;">β-cells</a>&nbsp;of the&nbsp;<a href="https://en.wikipedia.org/wiki/Pancreas" title="Pancreas" style="color: rgb(11, 0, 128); background-image: none;">pancreas</a>, in varying ratios depending upon the species.<sup id="cite_ref-pmid8243826_3-0" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-pmid8243826-3" style="color: rgb(11, 0, 128); background-image: none;">[3]</a></sup>&nbsp;Together, these two enzymes maintain the major physiological supply of GABA in mammals,<sup id="cite_ref-ReferenceA_2-1" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-ReferenceA-2" style="color: rgb(11, 0, 128); background-image: none;">[2]</a></sup>&nbsp;though it may also be synthesized from&nbsp;<a href="https://en.wikipedia.org/wiki/Putrescine" title="Putrescine" style="color: rgb(11, 0, 128); background-image: none;">putrescine</a>&nbsp;in the&nbsp;<a href="https://en.wikipedia.org/wiki/Enteric_nervous_system" title="Enteric nervous system" style="color: rgb(11, 0, 128); background-image: none;">enteric nervous system</a>,<sup id="cite_ref-:0_4-0" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-:0-4" style="color: rgb(11, 0, 128); background-image: none;">[4]</a></sup>&nbsp;brain,<sup id="cite_ref-5" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-5" style="color: rgb(11, 0, 128); background-image: none;">[5]</a></sup><sup id="cite_ref-:1_6-0" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-:1-6" style="color: rgb(11, 0, 128); background-image: none;">[6]</a></sup>&nbsp;and elsewhere by the actions of&nbsp;<a href="https://en.wikipedia.org/wiki/Diamine_oxidase" title="Diamine oxidase" style="color: rgb(11, 0, 128); background-image: none;">diamine oxidase</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/ALDH1A1" title="ALDH1A1" style="color: rgb(11, 0, 128); background-image: none;">aldehyde dehydrogenase 1a1</a>.<sup id="cite_ref-:0_4-1" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-:0-4" style="color: rgb(11, 0, 128); background-image: none;">[4]</a></sup><sup id="cite_ref-:1_6-1" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-:1-6" style="color: rgb(11, 0, 128); background-image: none;">[6]</a>&nbsp;</sup>Several truncated transcripts and polypeptides of GAD<sub style="line-height: 1; font-size: 11px;">67</sub>&nbsp;are detectable in the developing brain,<sup id="cite_ref-pmid7935469_7-0" class="reference" style="line-height: 1; unicode-bidi: -webkit-isolate; white-space: nowrap; font-size: 11px;"><a href="https://en.wikipedia.org/wiki/Glutamate_decarboxylase#cite_note-pmid7935469-7" style="color: rgb(11, 0, 128); background-image: none;">[7]</a></sup>&nbsp;however their function, if any, is unknown.</p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><div class="c-article-header" style="margin: 0px 0px 40px; padding: 0px; color: rgb(34, 34, 34); font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen-Sans, Ubuntu, Cantarell, 'Helvetica Neue', sans-serif; font-size: 18px; line-height: 31px;"><header><ul class="c-article-identifiers" data-test="article-identifier" style="margin-top: 0px; margin-right: 0px; margin-bottom: 8px; list-style: none; font-size: 1.6rem; line-height: 1.3; display: -webkit-flex; -webkit-flex-wrap: wrap; color: rgb(111, 111, 111); padding: 0px;"><li class="c-article-identifiers__item" style="border-right-width: 1px; border-right-style: solid; border-right-color: rgb(111, 111, 111); margin-right: 8px; padding-right: 8px; list-style: none;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Article</span></li><li class="c-article-identifiers__item" style="border-right-width: 1px; border-right-style: solid; border-right-color: rgb(111, 111, 111); margin-right: 8px; padding-right: 8px; list-style: none;"><span class="c-article-identifiers__open" style="color: rgb(204, 75, 20); font-family: Batang, 바탕, serif; font-size: 11pt;">Open Access</span></li><li class="c-article-identifiers__item" style="border-right-width: 0px; margin-right: 0px; padding-right: 0px; list-style: none;"><a href="https://www.nature.com/articles/s41467-019-08294-y#article-info" data-track="click" data-track-action="publication date" data-track-category="article body" data-track-label="link" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Published:</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><time datetime="2019-01-18" itemprop="datePublished"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">18 January 2019</span></time></a></li></ul><h1 class="c-article-title u-h1" data-test="article-title" data-article-title="" itemprop="name headline" style="margin: 0px 0px 16px; font-size: 3rem; padding: 0px; font-family: Harding, Lora, Palatino, Times, 'Times New Roman', serif; line-height: 1.4;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt; color: rgb(255, 0, 0);">Gut bacterial tyrosine decarboxylases restrict levels of levodopa in the treatment of Parkinson’s disease</span></h1><ul class="c-author-list js-list-authors js-etal-collapsed" data-etal="25" data-etal-small="3" data-test="authors-list" style="margin-top: 0px; margin-bottom: 0px; font-size: 1.6rem; list-style: none; padding: 0px; width: 602px;"><li class="c-author-list__item" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://www.nature.com/articles/s41467-019-08294-y#auth-1" class="js-no-scroll" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Sebastiaan P. van Kessel</span></a></span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">,</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span></li><li class="c-author-list__item" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://www.nature.com/articles/s41467-019-08294-y#auth-2" class="js-no-scroll" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Alexandra K. Frye</span></a></span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">,</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span></li><li class="c-author-list__item js-smaller-author-etal" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://www.nature.com/articles/s41467-019-08294-y#auth-3" class="js-no-scroll" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Ahmed O. El-Gendy</span></a></span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">,</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span></li><li class="c-author-list__item js-smaller-author-etal" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://www.nature.com/articles/s41467-019-08294-y#auth-4" class="js-no-scroll" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Maria Castejon</span></a></span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">,</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span></li><li class="c-author-list__item js-smaller-author-etal" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://www.nature.com/articles/s41467-019-08294-y#auth-5" class="js-no-scroll" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Ali Keshavarzian</span></a></span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">,</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span></li><li class="c-author-list__item js-smaller-author-etal" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://www.nature.com/articles/s41467-019-08294-y#auth-6" class="js-no-scroll" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Gertjan van Dijk</span></a></span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&amp;</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span></li><li class="c-author-list__item" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://www.nature.com/articles/s41467-019-08294-y#auth-7" data-corresp-id="c1" class="js-no-scroll" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Sahar El Aidy</span><svg width="16" height="16" class="u-icon"><use xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#global-icon-email"></use></svg></a></span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span></li></ul><p class="c-article-info-details" data-container-section="info" style="margin-top: 16px; margin-bottom: 8px; font-size: 1.6rem;"><a data-test="journal-link" href="https://www.nature.com/ncomms" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><i data-test="journal-title"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Nature Communications</span></i></a><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span data-test="journal-volume"><span class="u-visually-hidden" style="border: 0px; clip: rect(0px, 0px, 0px, 0px); height: 1px; margin: -1000px; overflow: hidden; padding: 0px; width: 1px; position: absolute !important; font-family: Batang, 바탕, serif; font-size: 11pt;">volume</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;10</span></span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">, Article&nbsp;number:&nbsp;</span><span data-test="article-number" style="font-family: Batang, 바탕, serif; font-size: 11pt;">310</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">(</span><span data-test="article-publication-year" style="font-family: Batang, 바탕, serif; font-size: 11pt;">2019</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">)</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><a href="https://www.nature.com/articles/s41467-019-08294-y#citeas" class="c-article-info-details__cite-as u-hide-print" data-track="click" data-track-action="cite this article" data-track-category="article body" data-track-label="link" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline; border-left-width: 1px; border-left-style: solid; border-left-color: rgb(111, 111, 111); margin-left: 8px; padding-left: 8px;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Cite this article</span></a></p><div class="c-article-metrics-bar__wrapper u-clear-both" style="margin: 0px; padding: 0px;"><ul class="c-article-metrics-bar u-list-inline" style="margin-top: 0px; margin-right: 0px; margin-bottom: 0px; list-style: none; padding: 0px; display: -webkit-flex; -webkit-flex-wrap: wrap; line-height: 1.3; font-size: 1.6rem;"><li class=" c-article-metrics-bar__item" style="-webkit-box-align: baseline; -webkit-align-items: baseline; border-right-width: 1px; border-right-style: solid; border-right-color: rgb(111, 111, 111); margin-right: 8px; display: inline;"><p class="c-article-metrics-bar__count" style="font-weight: 700;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">12k</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span class="c-article-metrics-bar__label" style="color: rgb(98, 98, 98); font-weight: 400; margin: 0px 10px 0px 5px; font-family: Batang, 바탕, serif; font-size: 11pt;">Accesses</span></p></li><li class="c-article-metrics-bar__item" style="-webkit-box-align: baseline; -webkit-align-items: baseline; border-right-width: 1px; border-right-style: solid; border-right-color: rgb(111, 111, 111); margin-right: 8px; display: inline;"><p class="c-article-metrics-bar__count" style="font-weight: 700;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">29</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span class="c-article-metrics-bar__label" style="color: rgb(98, 98, 98); font-weight: 400; margin: 0px 10px 0px 5px; font-family: Batang, 바탕, serif; font-size: 11pt;">Citations</span></p></li><li class="c-article-metrics-bar__item" style="-webkit-box-align: baseline; -webkit-align-items: baseline; border-right-width: 1px; border-right-style: solid; border-right-color: rgb(111, 111, 111); margin-right: 8px; display: inline;"><p class="c-article-metrics-bar__count" style="font-weight: 700;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">166</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span class="c-article-metrics-bar__label" style="color: rgb(98, 98, 98); font-weight: 400; margin: 0px 10px 0px 5px; font-family: Batang, 바탕, serif; font-size: 11pt;">Altmetric</span></p></li><li class="c-article-metrics-bar__item" style="-webkit-box-align: baseline; -webkit-align-items: baseline; border-right-width: 0px; margin-right: 8px; display: inline;"><p class="c-article-metrics-bar__details"><a href="https://www.nature.com/articles/s41467-019-08294-y/metrics" data-track="click" data-track-action="view metrics" data-track-category="article body" data-track-label="link" rel="nofollow" style="background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(0, 102, 153); vertical-align: baseline;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Metrics</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span class="u-visually-hidden" style="border: 0px; clip: rect(0px, 0px, 0px, 0px); height: 1px; margin: -1000px; overflow: hidden; padding: 0px; width: 1px; position: absolute !important; font-family: Batang, 바탕, serif; font-size: 11pt;">details</span></a></p></li></ul></div></header></div><div data-article-body="true" data-track-component="article body" class="c-article-body" style="margin: 0px; padding: 0px; clear: both; color: rgb(34, 34, 34); font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen-Sans, Ubuntu, Cantarell, 'Helvetica Neue', sans-serif; font-size: 18px; line-height: 31px;"><section aria-labelledby="Abs1" lang="en"><div class="c-article-section" id="Abs1-section" style="margin: 0px; padding: 0px; font-family: Lora, Palatino, Times, 'Times New Roman', serif; clear: both;"><h2 class="c-article-section__title u-h2 js-section-title js-c-reading-companion-sections-item" id="Abs1" style="font-size: 2.4rem; margin: 0px 0px 8px; padding: 0px; font-family: Harding, Lora, Palatino, Times, 'Times New Roman', serif; line-height: 1.4; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(213, 213, 213);"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Abstract</span></h2><div class="c-article-section__content" id="Abs1-content" style="margin: 0px 0px 40px; padding: 0px;"><p style="margin-bottom: 28px; word-wrap: break-word;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Human gut microbiota senses its environment and responds by releasing metabolites, some of which are key regulators of human health and disease. In this study, we characterize<b><span style="color: rgb(255, 0, 0);"> gut-associated bacteria in their ability to decarboxylate levodopa to dopamine via tyrosine decarboxylases</span></b>. <b><span style="color: rgb(9, 0, 255);">Bacterial tyrosine decarboxylases efficiently convert levodopa to dopamine, even in the presence of tyrosine, a competitive substrate, or inhibitors of human decarboxylase</span></b>. In situ levels of levodopa are compromised by high abundance of gut bacterial tyrosine decarboxylase in patients with Parkinson’s disease. Finally, the higher relative abundance of bacterial tyrosine decarboxylases at the site of levodopa absorption, proximal small intestine, had a significant impact on levels of levodopa in the plasma of rats. Our results highlight the role of microbial metabolism in drug availability, and specifically, that abundance of bacterial tyrosine decarboxylase in the proximal small intestine can explain the increased dosage regimen of levodopa treatment in Parkinson’s disease patients.</span></p></div></div></section></div><p><span style="font-size: 15px; line-height: 23px;"><b>에너지 대사경로와 이에 따른 아미노산 분류</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(9, 0, 255);">아미노산이 탈아미노반응 후 탄소골격이 시트르산 회로로 들어가는 경로는 포도당을 생성하거나 케톤을 생성</span></b>하여 들어감. 각 아미노산의 에너지 대사경로는 아래와 같음.&nbsp;&nbsp;<b><span style="color: rgb(255, 0, 0);">대사경로를 따라 케톤체를 만드는 아미노산(케톤성 아미노산)과 포도당을 생성하는 아미노산(당원성 아미노산) 그리고 두가지를 모두 생성하는 아미노산으로 분류</span></b>됨. 이들 <b><span style="color: rgb(0, 85, 255);">모두 아세틸 CoA를 생성하지만 당원성 아미노산은 시트르산 회로의 중간물질이 되어 당합성(포도당, 글리코겐의 합성) 반응의 원료</span></b>가 됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);"><br></span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">케톤성 아미노산은 류신과 리신</span></b>이며 그외는 탄소골격이 대사도중에 일부가 당원성이 됨. 최종적으로는 이들 모두는 <b><span style="color: rgb(9, 0, 255);">탄산가스와 물로 산화, 분해되며 이 과정에서 에너지 화합물인 ATP 생성</span></b>에 관여함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">시스테인, 세린, 트레오닌 --&gt; 피루브산 --&gt; 옥살아세트산 --&gt; 시트르산</span></p><p><span style="font-size: 15px; line-height: 23px;">이소류신, 류신, 트립토판 --&gt; 아세틸 &nbsp;CoA --&gt; 시트르산</span></p><p><span style="font-size: 15px; line-height: 23px;">류신, 리신, 티로신, 페닐알라닌, 트립토판 --&gt; 아세토아세틸 CoA --&gt; 아세틸 CoA --&gt; 시트르산</span></p><p><span style="font-size: 15px; line-height: 23px;">아스파라긴, 아스파르트산 --&gt; 옥살아세트산 --&gt; 시트르산</span></p><p><span style="font-size: 15px; line-height: 23px;">티로신, 페닐알라닌, 아스파르트산 --&gt; 푸마르산 --&gt; 옥살아세트산 --&gt; 시트르산</span></p><p><span style="font-size: 15px; line-height: 23px;">이소류신, 메티오닌, 발린 --&gt; 숙신 CoA --&gt; 푸마르산 --&gt; 옥살아세트산 --&gt; 시트르산</span></p><p><span style="font-size: 15px; line-height: 23px;">글루탐산, 글루타민, 히스티딘, 프롤린, 아르기닌 - 알파케토글루타르산 --&gt; 숙신 CoA --&gt; 푸마르산</span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/994F55385E52FF9C1B" class="txc-image" actualwidth="295" hspace="1" vspace="1" border="0" width="295" exif="{}" data-filename="스크린샷 2020-02-24 오전 7.41.00.png" style="clear:none;float:none;" id="A_994F55385E52FF9C1B18DE"/></p><p></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/994F3B385E52FF9C1B" class="txc-image" actualwidth="300" hspace="1" vspace="1" border="0" width="300" exif="{}" data-filename="스크린샷 2020-02-24 오전 7.40.54.png" style="clear:none;float:none;" id="A_994F3B385E52FF9C1B53E3"/></p><p><br></p><table class="txc-table" width="700" cellspacing="0" cellpadding="0" border="0" style="border:none;border-collapse:collapse;;font-family:gulim;font-size:12px"><tbody><tr><td style="width:350px;height:24px;border-bottom:1px solid #ccc;border-right:1px solid #ccc;border-top:1px solid #ccc;border-left:1px solid #ccc;;"><p><b><span style="font-size: 11pt;"><span style="color: rgb(9, 0, 255);">아</span><span style="color: rgb(9, 0, 255);">미노산</span></span><span style="font-size: 11pt; color: rgb(9, 0, 255);">&nbsp;</span></b></p></td><td style="width:350px;height:24px;border-bottom:1px solid #ccc;border-right:1px solid #ccc;border-top:1px solid #ccc;;"><p><span style="font-size: 11pt;"><b><span style="color: rgb(9, 0, 255);">아민&nbsp;</span></b></span></p></td></tr><tr><td style="width:350px;height:24px;border-bottom:1px solid #ccc;border-right:1px solid #ccc;border-left:1px solid #ccc;;"><p><span style="font-size: 11pt;">3,4 -비스히드록시 <b><span style="color: rgb(255, 0, 0);">페닐알라닌</span></b></span><span style="font-size: 11pt;"><b><span style="color: rgb(255, 0, 0);">&nbsp;</span></b></span></p></td><td style="width:350px;height:24px;border-bottom:1px solid #ccc;border-right:1px solid #ccc;;"><p><span style="font-size: 11pt;"><b><span style="color: rgb(255, 0, 0);">도파민&nbsp;</span></b></span></p></td></tr><tr><td style="width: 350px; height: 25px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-left-width: 1px; border-left-style: solid; border-left-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;"><b>히스티딘&nbsp;</b></span></p></td><td style="width: 350px; height: 25px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;"><b>히스타민&nbsp;</b></span></p></td></tr><tr><td style="width: 350px; height: 25px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204); border-left-width: 1px; border-left-style: solid; border-left-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;"><b><span style="color: rgb(255, 0, 0);">5, 히드록시 트립토</span><span style="color: rgb(255, 0, 0);">판&nbsp;</span></b></span></p></td><td style="width: 350px; height: 25px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(204, 204, 204); border-right-width: 1px; border-right-style: solid; border-right-color: rgb(204, 204, 204);"><p><span style="font-size: 11pt;"><b><span style="color: rgb(255, 0, 0);">세로토닌&nbsp;</span></b></span></p></td></tr><tr><td style="width:350px;height:24px;border-bottom:1px solid #ccc;border-right:1px solid #ccc;border-left:1px solid #ccc;;"><p><span style="font-size: 11pt;">리신&nbsp;</span></p></td><td style="width:350px;height:24px;border-bottom:1px solid #ccc;border-right:1px solid #ccc;;"><p><span style="font-size: 11pt;">카다베린&nbsp;</span></p></td></tr><tr><td style="width:350px;height:24px;border-bottom:1px solid #ccc;border-right:1px solid #ccc;border-left:1px solid #ccc;;"><p><span style="font-size: 11pt;"><b><span style="color: rgb(255, 0, 0);">글루타민산&nbsp;</span></b></span></p></td><td style="width:350px;height:24px;border-bottom:1px solid #ccc;border-right:1px solid #ccc;;"><p><span style="font-size: 11pt;"><b><span style="color: rgb(255, 0, 0);">감마-아미노부티르산 (GABA)</span></b></span></p></td></tr></tbody></table><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><div class="c-article-header" style="box-sizing: inherit; margin: 0px 0px 40px; padding: 0px; color: rgb(51, 51, 51); font-family: -apple-system, system-ui, 'Segoe UI', Roboto, Oxygen-Sans, Ubuntu, Cantarell, 'Helvetica Neue', sans-serif; font-size: 18px; orphans: 2; widows: 2; background-color: rgb(252, 252, 252);"><header style="box-sizing: inherit;"><ul class="c-article-identifiers" data-test="article-identifier" style="box-sizing: inherit; margin-top: 0px; margin-right: 0px; margin-bottom: 8px; list-style: none; font-size: 1.6rem; font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen-Sans, Ubuntu, Cantarell, 'Helvetica Neue', sans-serif; line-height: 1.3; color: rgb(111, 111, 111); padding: 0px;"><li class="c-article-identifiers__item" data-test="article-category" style="box-sizing: inherit; border-right: 1px solid rgb(111, 111, 111); margin-right: 8px; padding-right: 8px; list-style: none;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">Review</span></li><li class="c-article-identifiers__item" style="box-sizing: inherit; border-right: 0px; margin-right: 0px; padding-right: 0px; list-style: none;"><a href="https://link.springer.com/article/10.1007/s12272-019-01196-z#article-info" data-track="click" data-track-action="publication date" data-track-category="article body" data-track-label="link" style="box-sizing: inherit; background-color: transparent; color: rgb(0, 102, 153);"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">Published:</span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">&nbsp;</span><time datetime="2019-11-30" itemprop="datePublished" style="box-sizing: inherit;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">30 November 2019</span></time></a></li></ul><h1 class="c-article-title u-h1" data-test="article-title" data-article-title="" itemprop="name headline" style="box-sizing: inherit; margin: 0px 0px 16px; font-size: 3rem; font-family: Georgia, Palatino, serif; line-height: 1.4;"><span style="font-family: Batang, 바탕, serif; font-size: 14pt; color: rgb(9, 0, 255);">The regulation of glutamic acid decarboxylases in GABA neurotransmission in the brain</span></h1><ul class="c-author-list js-etal-collapsed" data-etal="25" data-etal-small="3" data-test="authors-list" data-component-authors-activator="authors-list" style="box-sizing: inherit; margin-top: 0px; font-size: 1.6rem; font-family: -apple-system, BlinkMacSystemFont, &quot;Segoe UI&quot;, Roboto, Oxygen-Sans, Ubuntu, Cantarell, &quot;Helvetica Neue&quot;, sans-serif; list-style: none; margin-bottom: 0px; padding: 0px; width: 751.281px;"><li class="c-author-list__item" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="box-sizing: inherit; margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name" style="box-sizing: inherit;"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://link.springer.com/article/10.1007/s12272-019-01196-z#auth-1" class="js-no-scroll" style="box-sizing: inherit; background-color: transparent; text-decoration: underline; color: rgb(69, 0, 167); text-decoration-skip-ink: auto;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">Seong-Eun Lee</span></a></span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">,</span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">&nbsp;</span></li><li class="c-author-list__item" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="box-sizing: inherit; margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name" style="box-sizing: inherit;"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://link.springer.com/article/10.1007/s12272-019-01196-z#auth-2" class="js-no-scroll" style="box-sizing: inherit; background-color: transparent; text-decoration: underline; color: rgb(69, 0, 167); text-decoration-skip-ink: auto;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">Yunjong Lee</span></a></span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">&nbsp;</span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">&amp;</span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">&nbsp;</span></li><li class="c-author-list__item" itemprop="author" itemscope="itemscope" itemtype="http://schema.org/Person" style="box-sizing: inherit; margin-left: 0px; display: inline; padding-right: 0px;"><span itemprop="name" style="box-sizing: inherit;"><a data-test="author-name" data-track="click" data-track-action="open author" data-track-category="article body" data-track-label="link" href="https://link.springer.com/article/10.1007/s12272-019-01196-z#auth-3" data-corresp-id="c1" class="js-no-scroll" style="box-sizing: inherit; background-color: transparent; text-decoration: underline; color: rgb(69, 0, 167); text-decoration-skip-ink: auto;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">Gum Hwa Lee</span><svg width="16" height="16" class="u-icon"><use xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="#global-icon-email"><svg id="global-icon-email" viewBox="0 0 18 18"><path d="M1.995 2h14.01A2 2 0 0118 4.006v9.988A2 2 0 0116.005 16H1.995A2 2 0 010 13.994V4.006A2 2 0 011.995 2zM1 13.994A1 1 0 001.995 15h14.01A1 1 0 0017 13.994V4.006A1 1 0 0016.005 3H1.995A1 1 0 001 4.006zM9 11L2 7V5.557l7 4 7-4V7z" fill-rule="evenodd"></path></svg></use></svg></a></span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">&nbsp;</span></li></ul><p class="c-article-info-details" data-container-section="info" style="box-sizing: inherit; margin-top: 16px; margin-bottom: 8px; font-size: 1.6rem; font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen-Sans, Ubuntu, Cantarell, 'Helvetica Neue', sans-serif;"><a data-test="journal-link" href="https://link.springer.com/journal/12272" style="box-sizing: inherit; background-color: transparent; text-decoration: underline; color: rgb(69, 0, 167); text-decoration-skip-ink: auto;"><i data-test="journal-title" style="box-sizing: inherit;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">Archives of Pharmacal Research</span></i></a><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">&nbsp;</span><span data-test="journal-volume" style="box-sizing: inherit;"><span class="u-visually-hidden" style="box-sizing: inherit; border: 0px; clip: rect(0px, 0px, 0px, 0px); height: 1px; margin: -1585px; overflow: hidden; padding: 0px; width: 1px; position: absolute !important; font-family: Batang, 바탕, serif; font-size: 12pt;">volume</span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">&nbsp;42</span></span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">,&nbsp;</span><span class="u-visually-hidden" style="box-sizing: inherit; border: 0px; clip: rect(0px, 0px, 0px, 0px); height: 1px; margin: -1585px; overflow: hidden; padding: 0px; width: 1px; position: absolute !important; font-family: Batang, 바탕, serif; font-size: 12pt;">pages</span><span itemprop="pageStart" style="box-sizing: inherit; font-family: Batang, 바탕, serif; font-size: 12pt;">1031</span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">&#8211;</span><span itemprop="pageEnd" style="box-sizing: inherit; font-family: Batang, 바탕, serif; font-size: 12pt;">1039</span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">(</span><span data-test="article-publication-year" style="box-sizing: inherit; font-family: Batang, 바탕, serif; font-size: 12pt;">2019</span><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">)</span><a href="https://link.springer.com/article/10.1007/s12272-019-01196-z#citeas" class="c-article-info-details__cite-as u-hide-print" data-track="click" data-track-action="cite this article" data-track-category="article body" data-track-label="link" style="box-sizing: inherit; background-color: transparent; text-decoration: underline; color: rgb(69, 0, 167); text-decoration-skip-ink: auto; border-left: 1px solid rgb(111, 111, 111); margin-left: 8px; padding-left: 8px;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">Cite this article</span></a></p><div data-test="article-metrics" style="box-sizing: inherit; margin: 0px; padding: 0px;"><div id="altmetric-container" style="box-sizing: inherit; margin: 0px; padding: 0px;"><div class="c-article-metrics-bar__wrapper u-clear-both" style="box-sizing: inherit; margin: 0px; padding: 0px;"><ul class="c-article-metrics-bar u-list-inline" style="box-sizing: inherit; margin-top: 0px; margin-right: 0px; margin-bottom: 0px; list-style: none; padding: 0px; line-height: 1.3; font-size: 1.6rem; font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen-Sans, Ubuntu, Cantarell, 'Helvetica Neue', sans-serif;"><li class=" c-article-metrics-bar__item" style="box-sizing: inherit; -webkit-box-align: baseline; align-items: baseline; border-right: 1px solid rgb(111, 111, 111); margin-right: 8px; display: inline;"><p class="c-article-metrics-bar__count" style="box-sizing: inherit; font-weight: 700;"><span style="font-size: 12pt; font-weight: 400; line-height: 1.4; font-family: Batang, 바탕, serif;">Abstract</span><br></p></li></ul></div></div></div></header></div><div data-article-body="true" data-track-component="article body" class="c-article-body" style="box-sizing: inherit; margin: 0px; padding: 0px; clear: both; color: rgb(51, 51, 51); font-family: -apple-system, system-ui, 'Segoe UI', Roboto, Oxygen-Sans, Ubuntu, Cantarell, 'Helvetica Neue', sans-serif; font-size: 18px; orphans: 2; widows: 2; background-color: rgb(252, 252, 252);"><section aria-labelledby="Abs1" lang="en" style="box-sizing: inherit;"><div class="c-article-section" id="Abs1-section" style="box-sizing: inherit; margin: 0px; padding: 0px; font-family: Georgia, Palatino, serif; clear: both;"><div class="c-article-section__content" id="Abs1-content" style="box-sizing: inherit; margin: 0px 0px 40px; padding: 0px;"><p style="box-sizing: inherit; margin-bottom: 1.5em; overflow-wrap: break-word; line-height: 1.8;"><span style="font-family: Batang, 바탕, serif; font-size: 12pt;">Gamma-aminobutyric acid (GABA) is the main inhibitory neurotransmitter that is required for the control of synaptic excitation/inhibition and neural oscillation. <b><span style="color: rgb(9, 0, 255);">GABA is synthesized by glutamic acid decarboxylases (GADs) that are widely distributed and localized to axon terminals of inhibitory neurons as well as to the soma and, to a lesser extent, dendrites.</span></b> The expression&#8206; and activity of GADs is highly correlated with GABA levels and subsequent GABAergic neurotransmission at the inhibitory synapse. <b><span style="color: rgb(255, 0, 0);">Dysregulation of GADs has been implicated in various neurological disorders including epilepsy and schizophrenia</span></b>. Two isoforms of GADs, GAD67 and GAD65, are expressed from separate genes and have different regulatory processes and molecular properties. <b><span style="color: rgb(255, 0, 0);">This review focuses on the recent advances in understanding the structure of GAD, its transcriptional regulation and post-transcriptional modifications in the central nervous system. This may provide insights into the pathological mechanisms underlying neurological diseases that are associated with GAD dysfunction.</span></b></span></p></div></div></section></div><div class="widget widget-ArticleTopInfo widget-instance-OUP_ArticleTop_Info_Widget" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-stretch: inherit; font-size: 1.0625rem; line-height: 1.5em; font-family: Merriweather, serif; vertical-align: baseline; color: rgb(42, 42, 42); orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><div class="module-widget article-top-widget" style="box-sizing: border-box; margin: 0px 0px 1.25rem; padding: 0px; border: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: 'Source Sans Pro', sans-serif; vertical-align: baseline;"><div class="widget-items" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><h1 class="wi-article-title article-title-main" style="box-sizing: border-box; margin: 0px 0px 0.1rem; padding: 0px; border: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-family: Merriweather, serif; vertical-align: baseline; font-size: 24px !important; line-height: 1.37 !important;">Tyrosine, Phenylalanine, and Catecholamine Synthesis and Function in the Brain&nbsp;<span class="icon-availability_free" title="Free" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-weight: normal; font-stretch: inherit; font-size: inherit; line-height: 1; vertical-align: baseline; speak: none; -webkit-font-smoothing: antialiased; color: rgb(47, 145, 98); font-family: icomoon !important;"></span></h1><div class="wi-authors" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><div class="al-authors-list" style="box-sizing: border-box; margin: 0px 0px 11px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><span class="al-author-name-more" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: inline-block;"><a class="linked-name" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; color: rgb(0, 111, 183); overflow-wrap: break-word; word-break: break-word;">John D. Fernstrom</a><span class="delimiter" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><span class="icon-general-mail" style="box-sizing: border-box; margin: 0px; padding: 0px 2px 0px 6px; border: 0px; font-stretch: inherit; font-size: 0.8em; line-height: 1; vertical-align: baseline; speak: none; -webkit-font-smoothing: antialiased; font-family: icomoon !important;"></span>,</span></span>&nbsp;<span class="al-author-name-more" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: inline-block;"><a class="linked-name" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; color: rgb(0, 111, 183); overflow-wrap: break-word; word-break: break-word;">Madelyn H. Fernstrom</a><span class="delimiter" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"></span></span></div></div><div class="pub-history-wrap clearfix" style="box-sizing: border-box; margin: 11px 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><div class="pub-history-row clearfix" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><div class="ww-citation-primary" style="box-sizing: border-box; margin: 0px 15px 0px 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: inline;"><em style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-variant: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline;">The Journal of Nutrition</em>, Volume 137, Issue 6, June 2007, Pages 1539S&#8211;1547S,&nbsp;<a href="https://doi.org/10.1093/jn/137.6.1539S" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; color: rgb(0, 111, 183); overflow-wrap: break-word; word-break: break-word;">https://doi.org/10.1093/jn/137.6.1539S</a></div></div><div class="pub-history-row clearfix" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><div class="ww-citation-date-wrap" style="box-sizing: border-box; margin: 0px 20px 0px 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: inline-block;"><div class="citation-label" style="box-sizing: border-box; margin: 0px 5px 0px 0px; padding: 0px; border: 0px; font-style: inherit; font-variant: inherit; font-weight: bold; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: inherit; vertical-align: baseline; display: inline;">Published:</div>&nbsp;<div class="citation-date" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: inline;">01 June 2007</div></div></div></div></div></div></div><div class="widget widget-ArticleLinks widget-instance-OUP_Article_Links_Widget" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-stretch: inherit; font-size:12pt; line-height: inherit; font-family: Merriweather, serif; vertical-align: baseline; color: rgb(42, 42, 42); orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"></div><div class="article-body js-content-body" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-stretch: inherit; font-size:12pt; line-height: inherit; font-family: Merriweather, serif; vertical-align: baseline; position: relative; overflow-wrap: break-word; color: rgb(42, 42, 42); orphans: 2; widows: 2; background-color: rgb(255, 255, 255);"><div class="toolbar-wrap js-toolbar-wrap" style="box-sizing: border-box; margin: 0px 0px 0.5rem; padding: 0px; border-width: 0px 0px 1px; border-bottom-style: solid; border-bottom-color: rgb(207, 213, 228); font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><div class="toolbar-inner-wrap" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: table;"><ul id="Toolbar" role="navigation" style="box-sizing: border-box; margin-top: 0px; margin-right: 0px; margin-bottom: 0px; padding: 0px; border: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; font-family: 'Source Sans Pro', sans-serif; vertical-align: baseline; list-style: none; clear: both; float: left;"><li class="toolbar-item item-pdf" style="box-sizing: border-box; margin: 0px 2em 0px 0px; padding: 0px 0px 0.25em; border-top-style: none; border-right-width: 0px; border-bottom-style: none; border-left-width: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: 1.0625rem; line-height: 30px; font-family: inherit; vertical-align: baseline; float: left; text-align: left; position: relative;"><a class="al-link pdf article-pdfLink" data-article-id="4664857" href="https://academic.oup.com/jn/article-pdf/137/6/1539S/30006682/1539s.pdf" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; color: black; display: inline; overflow-wrap: break-word; word-break: break-word;"><img src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Foup.silverchair-cdn.com%2FUI%2Fapp%2Fsvg%2Fpdf.svg" alt="pdf" style="box-sizing: border-box; max-width: 100%; height: 24px; display: inline-block; vertical-align: middle; margin: 0px 7px 4px 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; width: 19.03px;"><span class="pdf-link-text" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;">PDF</span></a></li><li class="toolbar-item item-link item-split-view" style="box-sizing: border-box; margin: 0px 2em 0px 0px; padding: 0px 0px 0.25em; border-top-style: none; border-right-width: 0px; border-bottom-style: none; border-left-width: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: 1.0625rem; line-height: 30px; font-family: inherit; vertical-align: baseline; float: left; text-align: left; position: relative;"><a class="split-view js-split-view st-split-view" target="" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; color: black; display: inline; overflow-wrap: break-word; word-break: break-word;"><span class="icon-menu_split" style="box-sizing: border-box; margin: 0px 3px 0px 0px; padding: 0px; border: 0px; font-stretch: inherit; font-size: 0.9375rem; line-height: 1; vertical-align: baseline; speak: none; -webkit-font-smoothing: antialiased; display: inline-block; position: relative; top: -2px; font-family: icomoon !important;"></span>&nbsp;Split View</a></li><li class="toolbar-item" style="box-sizing: border-box; margin: 0px 2em 0px 0px; padding: 0px 0px 0.25em; border-top-style: none; border-right-width: 0px; border-bottom-style: none; border-left-width: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: 1.0625rem; line-height: 30px; font-family: inherit; vertical-align: baseline; float: left; text-align: left; position: relative;"><div class="widget widget-ToolboxGetCitation widget-instance-OUP_Get_Citation" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: inline-block;"><a href="https://academic.oup.com/jn/article/137/6/1539S/4664857#" class="js-cite-button" data-reveal-id="getCitation" data-reveal="" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; color: black; display: inline; overflow-wrap: break-word; word-break: break-word;"><span class="icon-read-more" style="box-sizing: border-box; margin: 0px 3px 0px 0px; padding: 0px; border: 0px; font-stretch: inherit; font-size: 0.9375rem; line-height: 1; vertical-align: baseline; speak: none; -webkit-font-smoothing: antialiased; display: inline-block; position: relative; top: -2px; font-family: icomoon !important;"></span><span style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;">Cite</span></a></div></li><li class="toolbar-item item-tools" style="box-sizing: border-box; margin: 0px 2em 0px 0px; padding: 0px 0px 0.25em; border-top-style: none; border-right-width: 0px; border-bottom-style: none; border-left-width: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: 1.0625rem; line-height: 30px; font-family: inherit; vertical-align: baseline; float: left; text-align: left; position: relative;"><div class="widget widget-ToolboxPermissions widget-instance-" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: inline-block;"><div class="module-widget" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><a href="https://s100.copyright.com/AppDispatchServlet?publisherName=OUP&amp;publication=1541-6100&amp;title=Tyrosine%2C%20Phenylalanine%2C%20and%20Catecholamine%20Synthesis%20and%20Function%20in%20the%20Brain&amp;publicationDate=2007-06-01&amp;volumeNum=137&amp;issueNum=6&amp;author=Fernstrom%2C%20John%20D.%3B%20Fernstrom%2C%20Madelyn%20H.&amp;startPage=1539S&amp;endPage=1547S&amp;contentId=10.1093%2Fjn%2F137.6.1539S&amp;oa=&amp;copyright=Oxford%20University%20Press&amp;orderBeanReset=True" id="PermissionsLink" class="" target="" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; color: black; display: inline; overflow-wrap: break-word; word-break: break-word;"><span class="icon-menu_permissions" style="box-sizing: border-box; margin: 0px 3px 0px 0px; padding: 0px; border: 0px; font-stretch: inherit; font-size: 0.9375rem; line-height: 1; vertical-align: baseline; speak: none; -webkit-font-smoothing: antialiased; display: inline-block; position: relative; top: -2px; font-family: icomoon !important;"><span class="screenreader-text" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; position: absolute; left: -10000px; top: auto; width: 1px; height: 1px; overflow: hidden;">Permissions Icon</span></span>&nbsp;Permissions</a></div></div></li><li class="toolbar-item item-with-dropdown item-share last" style="box-sizing: border-box; margin: 0px; padding: 0px 0px 0.25em; border-top-style: none; border-right-width: 0px; border-bottom-style: none; border-left-width: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: 1.0625rem; line-height: 30px; font-family: inherit; vertical-align: baseline; float: left; text-align: left; position: relative;"><a class="drop-trigger" data-dropdown="ShareDrop" aria-haspopup="true" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; color: black; display: inline; overflow-wrap: break-word; word-break: break-word;"><span class="icon-menu_share" style="box-sizing: border-box; margin: 0px 3px 0px 0px; padding: 0px; border: 0px; font-stretch: inherit; font-size: 0.9375rem; line-height: 1; vertical-align: baseline; speak: none; -webkit-font-smoothing: antialiased; display: inline-block; position: relative; top: -2px; font-family: icomoon !important;"></span>&nbsp;<div class="toolbar-label" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: inline-block;"><div class="toolbar-text" style="box-sizing: border-box; margin: 0px -2px 0px 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline; display: inline-block;">Share</div>&nbsp;<span class="icon-general-arrow-filled-down arrow-icon" style="box-sizing: border-box; margin: 0px 3px 0px 0px; padding: 0px 0px 0px 4px; border: 0px; font-stretch: inherit; font-size: 0.5rem; line-height: 1; vertical-align: baseline; speak: none; -webkit-font-smoothing: antialiased; top: -4px; display: inline-block; position: relative; font-family: icomoon !important;"></span></div></a></li></ul></div></div><div id="ContentTab" class="content active" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><div class="widget widget-ArticleFulltext widget-instance-OUP_Article_FullText_Widget" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><div class="module-widget" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><div class="widget-items" data-widgetname="ArticleFulltext" style="box-sizing: border-box; margin: 0px; padding: 0px; border: 0px; font-family: inherit; font-size: inherit; font-style: inherit; font-variant: inherit; line-height: inherit; vertical-align: baseline;"><h2 scrollto-destination="163364632" id="163364632" class="abstract-title" style="box-sizing: border-box; margin-top: 0px; margin-right: 0px; margin-left: 0px; padding: 1.5rem 1.2rem 0.9rem; border: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: 1.25rem; line-height: 1em; font-family: 'Source Sans Pro', sans-serif; vertical-align: baseline; background-color: rgb(239, 242, 247); margin-bottom: 0px !important; background-position: initial initial; background-repeat: initial initial;">Abstract</h2><section class="abstract" style="box-sizing: border-box; margin: 0px; padding: 0px 1.2rem 1.7rem; border: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: inherit; line-height: inherit; vertical-align: baseline; position: relative; background-color: rgb(239, 242, 247); background-position: initial initial; background-repeat: initial initial;"><p style="box-sizing: border-box; border: 0px; font-style: inherit; font-variant: inherit; font-stretch: inherit; font-size: 15px; line-height: 1.7em; font-family: inherit; vertical-align: baseline;">Aromatic amino acids in the brain function as precursors for the monoamine neurotransmitters serotonin (substrate tryptophan) and the catecholamines [dopamine, norepinephrine, epinephrine; substrate tyrosine (Tyr)]. Unlike almost all other neurotransmitter biosynthetic pathways, the rates of synthesis of serotonin and catecholamines in the brain are sensitive to local substrate concentrations, particularly in the ranges normally found in vivo. As a consequence, physiologic factors that influence brain pools of these amino acids, notably diet, influence their rates of conversion to neurotransmitter products, with functional consequences. This review focuses on Tyr and phenylalanine (Phe). Elevating brain Tyr concentrations stimulates catecholamine production, an effect exclusive to actively firing neurons. Increasing the amount of protein ingested, acutely (single meal) or chronically (intake over several days), raises brain Tyr concentrations and stimulates catecholamine synthesis. Phe, like Tyr, is a substrate for Tyr hydroxylase, the enzyme catalyzing the rate-limiting step in catecholamine synthesis. Tyr is the preferred substrate; consequently, unless Tyr concentrations are abnormally low, variations in Phe concentration do not affect catecholamine synthesis. Unlike Tyr, Phe does not demonstrate substrate inhibition. Hence, high concentrations of Phe do not inhibit catecholamine synthesis and probably are not responsible for the low production of catecholamines in subjects with phenylketonuria. Whereas neuronal catecholamine release varies directly with Tyr-induced changes in catecholamine synthesis, and brain functions linked pharmacologically to catecholamine neurons are predictably altered, the physiologic functions that utilize the link between Tyr supply and catecholamine synthesis/release are presently unknown. An attractive candidate is the passive monitoring of protein intake to influence protein-seeking behavior.</p></section></div></div></div></div></div><p><span style="font-size: 15px; line-height: 23px;"><b><br></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>3) 요소회로와 질소배설물</b><br></span></p><p><span style="font-size: 15px; line-height: 23px;">아미노산의 분해, 즉 <b><span style="color: rgb(255, 0, 0);">탈아미노반응 결과 떨어져 나온 질소는 암모니아를 형성함. 암모니아는 상당히 독성이 강하므로 독성이 없는 화합물인 요소로 전환, 배설하는 과정을 거침</span></b>. 즉 각 조직세포에서 생성된 유독한 암모니아는 알라닌 형태로 되어 혈액을 통해 간으로 운반된 후 이산화탄소와 결합하여 무해한 요소로 전환되는데 이 과정을 <b><span style="color: rgb(0, 85, 255);">요소회로(Urea cycle)</span></b>라고 함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">사람(척추동물)의 경우 요소는 요소회로에 의해 합성됨. 이 회로에 의해 합성되는 요소의 질소원자 또는탄소원자는 아스파르트산과 NH4+와 CO2에서 옴. 이 회로에서 탄소원자와 질소원자의 운반체 역할을 하는 화합물은 오르니틴임. 요소를 직접 생산하는 전구체는 아르기닌이며 이것은 아르기닌 가수분해효소의 작용에 의해 요소와 오르니틴으로 가수분해됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99CCDE355E54500B17" class="txc-image" actualwidth="496" hspace="1" vspace="1" border="0" width="496" exif="{}" data-filename="스크린샷 2020-02-25 오전 7.36.29.png" style="clear:none;float:none;" id="A_99CCDE355E54500B174F72"/></p><p></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">다음반응은 <b><span style="color: rgb(0, 85, 255);">시트룰린과 아스파르트산이 축합하여 아르기노숙신산이 합성되는 반응</span></b>임. 마지막으로 아르기노숙신산 분해효소가 아르기노숙신산을 아르기닌과 푸마르산으로 분해함. 요소회로에서 푸마르산이 생성되어 시트르산 회로와 연결됨. 생성된 요소는 신장으로 가서 소변으로 배설됨 .</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">소변 중 질소 성분배설량은 단백질 섭취량에 따라 다름</span></b>. 고단백 식이섭취 시에는 대부분 요소질소로 배설됨. 저단백 식이때보다 소변 중 총 질소와 요소배설량은 현저히 높음. 반면에 단백질 섭취량이 달라도 상대적으로 암모니아, 크레아틴 질소량은 변하지 않음. 기아시에도 질소량이 현저히 감소함. <b><span style="color: rgb(255, 0, 0);">간기능 이상으로 암모니아가 요소로 전환되지 못하면 혈중에 암모니아 농도가 높아지게 되어 중추신경계에 장애를 일으키는 간성혼수</span></b>를 유발할 수 있음.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/990CDC405E54515918" class="txc-image" actualwidth="525" hspace="1" vspace="1" border="0" width="525" exif="{}" data-filename="스크린샷 2020-02-25 오전 7.42.13.png" style="clear:none;float:none;" id="A_990CDC405E54515918DC6B"/></p><p></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>4) 조직내 아미노산 대사</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>가. 주요조직의 아미노산 대사</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;">식품단백질이<b><span style="color: rgb(255, 0, 0);"> 아미노산으로 완전히 소화된 후에 이 아미노산은 간문맥을 거쳐 간으로 운반되어 대사</span></b>되고 일부는 다시 혈액으로 나와 각 조직에 운반되어 단백질 합성을 위해 사용됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><h3 style="box-sizing: border-box; margin: 0px; padding: 0px; font-size: 1.2rem; line-height: 1.333; color: rgb(46, 46, 46); font-family: NexusSans, Arial, Helvetica, 'Lucida Sans Unicode', 'Microsoft Sans Serif', 'Segoe UI Symbol', STIXGeneral, 'Cambria Math', 'Arial Unicode MS', sans-serif;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">Hepatic Protein Metabolism</span></h3><p></p><div style="box-sizing: border-box; margin: 0px; padding: 0px; color: rgb(46, 46, 46); font-family: NexusSans, Arial, Helvetica, 'Lucida Sans Unicode', 'Microsoft Sans Serif', 'Segoe UI Symbol', STIXGeneral, 'Cambria Math', 'Arial Unicode MS', sans-serif; font-size: 20px; line-height: 28px;"><p id="B9780128042748000308-p0085" style="box-sizing: border-box; margin-bottom: 0.4em; line-height: 1.5em;"><span style="box-sizing: border-box; margin: 0px; padding: 0px;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">The main functions that the liver carries out in protein and</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><a href="https://www.sciencedirect.com/topics/medicine-and-dentistry/amino-acid-metabolism" title="Learn more about Amino Acid Metabolism from ScienceDirect's AI-generated Topic Pages" style="box-sizing: border-box; margin: 0px; padding: 0px; background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(12, 125, 187); -webkit-transition: color 0.3s ease, border-bottom-color 0.3s ease; transition: color 0.3s ease, border-bottom-color 0.3s ease;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">amino acid metabolism</span></a><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">include <b><span style="color: rgb(255, 0, 0);">amino acids synthesis, interconversion and deamination, plasma</span></b></span><b><span style="font-family: Batang, 바탕, serif; font-size: 11pt; color: rgb(255, 0, 0);">&nbsp;</span><a href="https://www.sciencedirect.com/topics/medicine-and-dentistry/protein-synthesis" title="Learn more about Protein Synthesis from ScienceDirect's AI-generated Topic Pages" style="box-sizing: border-box; margin: 0px; padding: 0px; background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(12, 125, 187); -webkit-transition: color 0.3s ease, border-bottom-color 0.3s ease; transition: color 0.3s ease, border-bottom-color 0.3s ease;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt; color: rgb(255, 0, 0);">protein synthesis</span></a><span style="font-family: Batang, 바탕, serif; font-size: 11pt; color: rgb(255, 0, 0);">, and</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt; color: rgb(255, 0, 0);">&nbsp;</span><a href="https://www.sciencedirect.com/topics/medicine-and-dentistry/urea-cycle" title="Learn more about Urea Cycle from ScienceDirect's AI-generated Topic Pages" style="box-sizing: border-box; margin: 0px; padding: 0px; background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(12, 125, 187); -webkit-transition: color 0.3s ease, border-bottom-color 0.3s ease; transition: color 0.3s ease, border-bottom-color 0.3s ease;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt; color: rgb(255, 0, 0);">urea synthesis</span></a></b><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">. <b><span style="color: rgb(9, 0, 255);">The liver is the only organ capable of eliminating nitrogen from amino acids via urea synthesis</span></b>. Amino acid metabolism in the liver is finely regulated and the liver is the key organ for maintaining amino acid</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><a href="https://www.sciencedirect.com/topics/medicine-and-dentistry/homeostasis" title="Learn more about Homeostasis from ScienceDirect's AI-generated Topic Pages" style="box-sizing: border-box; margin: 0px; padding: 0px; background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(12, 125, 187); -webkit-transition: color 0.3s ease, border-bottom-color 0.3s ease; transition: color 0.3s ease, border-bottom-color 0.3s ease;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">homeostasis</span></a><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">in circulation. The liver can use amino acids for synthesis of glucose and key molecules [e.g.,&nbsp;</span><a href="https://www.sciencedirect.com/topics/medicine-and-dentistry/creatinine" title="Learn more about Creatinine from ScienceDirect's AI-generated Topic Pages" style="box-sizing: border-box; margin: 0px; padding: 0px; background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(12, 125, 187); -webkit-transition: color 0.3s ease, border-bottom-color 0.3s ease; transition: color 0.3s ease, border-bottom-color 0.3s ease;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">creatinine</span></a><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">and</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><a href="https://www.sciencedirect.com/topics/medicine-and-dentistry/glutathione" title="Learn more about Glutathione from ScienceDirect's AI-generated Topic Pages" style="box-sizing: border-box; margin: 0px; padding: 0px; background-color: transparent; -webkit-text-decoration-skip: objects; color: rgb(12, 125, 187); -webkit-transition: color 0.3s ease, border-bottom-color 0.3s ease; transition: color 0.3s ease, border-bottom-color 0.3s ease;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">glutathione</span></a><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">(GSH)]. A general overview of amino acid metabolism in the liver is shown in</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">&nbsp;</span></span><span style="box-sizing: border-box; margin: 0px; padding: 0px; font-family: Batang, 바탕, serif; font-size: 11pt;">Fig.&nbsp;30.3</span><span style="font-family: Batang, 바탕, serif; font-size: 11pt;">.</span></p></div><p style="text-align: center;"></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 간</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(0, 85, 255);">간에서 혈장으로 유출되는 트립토판은 뇌로 가서 세로토닌 합성의 전구체로 사용</span></b>됨. 곁가지 아미노산은 말초조직 특히 근육에서 분해됨. <b><span style="color: rgb(255, 0, 0);">육류를 섭취한 후에 간에서 방출되는 아미노산의 70%가 분지(곁가지) 아미노산</span></b>임. 이는 육류단백질의 분지 아미노산은 간에서 분해가 잘 대사되지 않고 다른 아미노산들은 잘 분해되기 때문임. 이 분지 아미노산들은 근육에서 주로 분해됨.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>주요조직의 단백질 대사량</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(9, 0, 255);">단백질 섭취량을 100g으로 볼때 장에서 분비되는 단백질을 합해서 흡수량은 160g</span></b>임.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;">체내 단백질 양을 보면 체단백질 합성량 250g, 근육 50g, 유리아미노산 100g, 간에서 25g, 적혈구, 백혈구 20g, 헤모글로빈 8g 순으로 이용됨. 흡수된 단백질 중 소변으로 88g정도 배설되며 피부로도 2g배설됨.&nbsp;</span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/9905C24A5E552D670F" class="txc-image" actualwidth="333" hspace="1" vspace="1" border="0" width="333" exif="{}" data-filename="스크린샷 2020-02-25 오후 11.20.57.png" style="clear:none;float:none;" id="A_9905C24A5E552D670F02A8"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 근육</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">근육에서는 중성 아미노산인 알라닌과 글루타민이 주로 유출</span></b>됨. <b><span style="color: rgb(9, 0, 255);">알라닌은 간으로 이동하여 포도당 신생과정을 거쳐 혈당으로 재방출되어 근육으로 다시 흡수됨(포도당-알라닌 회로</span></b>). 글<b><span style="color: rgb(255, 0, 0);">루타민은 장으로 이동하여 알라닌이 된 후 다시 간으로 이동</span></b>함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/998D9B3A5E552F420F" class="txc-image" actualwidth="591" hspace="1" vspace="1" border="0" width="591" exif="{}" data-filename="스크린샷 2020-02-25 오후 11.28.57.png" style="clear:none;float:none;" id="A_998D9B3A5E552F420F4980"/></p><p></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/99B398465E552F8E09" class="txc-image" actualwidth="583" hspace="1" vspace="1" border="0" width="583" exif="{}" data-filename="스크린샷 2020-02-25 오후 11.30.12.png" style="clear:none;float:none;" id="A_99B398465E552F8E09024F"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>참고) DNA replication</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/994104505E55ABD01A" class="txc-image" actualwidth="470" hspace="1" vspace="1" border="0" width="470" exif="{}" data-filename="스크린샷 2020-02-26 오전 8.19.25.png" style="clear:none;float:none;" id="A_994104505E55ABD01AE2B9"/></p><p></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p style="text-align: center;"><img src="https://t1.daumcdn.net/cfile/cafe/9930D9475E55AC2D1A" class="txc-image" actualwidth="385" hspace="1" vspace="1" border="0" width="385" exif="{}" data-filename="스크린샷 2020-02-26 오전 8.21.56.png" style="clear:none;float:none;" id="A_9930D9475E55AC2D1A023A"/></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b># 일반조직</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">발린, 류신, 이소류신은 분지 아미노산으로 일상생활에서 섭취해야 하는 필수아미노산의 50%</span></b>를 차지함. 근육이나 뇌 등 일반조직에서 에너지원으로 사용되고 있음.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>나. 분지아미노산(branched-chain amino acid)의 대사</b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(9, 0, 255);">분지아미노산은 분지 아미노산 트랜스퍼라제에 의해 알파-케토산이 되고 산화적 탈산효소에 의해 분해되어 에너지 대사과정</span></b>으로 들어감.</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><br></p><p style="text-align: center;"></p><p></p><p style="text-align: center;"></p><p><span role="menubar" style="color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif; font-size: 0.8425em; line-height: 1.6363em;"><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5934885/#" role="menuitem" aria-expanded="false" aria-haspopup="true" style="color: rgb(100, 42, 143);">Nutr Metab (Lond)</a></span><span style="color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif; font-size: 0.8425em; line-height: 1.6363em;">. 2018; 15: 33.</span><span style="color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif; font-size: 0.8425em; line-height: 1.6363em;">&nbsp;</span></p><div class="fm-sec half_rhythm no_top_margin" style="margin: 0px 0px 0.6923em; font-size: 0.8425em; line-height: 1.6363em; font-family: arial, helvetica, clean, sans-serif; color: rgb(0, 0, 0);"><div class="fm-citation half_rhythm no_top_margin clearfix" style="margin: 0px 0px 0.6923em; zoom: 1;"><div class="inline_block eight_col va_top" style="max-width: 100%; vertical-align: top; display: inline-block; zoom: 1; width: 452.3125px;"><div><span class="fm-vol-iss-date">Published online 2018 May 3.&nbsp;</span><span class="doi" style="white-space: nowrap;">doi:&nbsp;<a href="https://dx.doi.org/10.1186%2Fs12986-018-0271-1" target="pmc_ext" ref="reftype=other&amp;article-id=5934885&amp;issue-id=304137&amp;journal-id=272&amp;FROM=Article%7CFront%20Matter&amp;TO=Content%20Provider%7CCrosslink%7CDOI" style="color: rgb(100, 42, 143);">10.1186/s12986-018-0271-1</a></span></div></div><div class="inline_block four_col va_top show-overflow align_right" style="max-width: 100%; vertical-align: top; text-align: right; display: inline-block; zoom: 1; width: 222.703125px;"><div class="fm-citation-ids"><div class="fm-citation-pmcid"><span class="fm-citation-ids-label">PMCID:&nbsp;</span>PMC5934885</div><div class="fm-citation-pmid">PMID:&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pubmed/29755574" style="color: rgb(100, 42, 143);">29755574</a></div></div></div></div><h1 class="content-title" style="font-size: 1.5384em; margin: 1em 0px 0.5em; line-height: 1.35em; font-weight: normal;">Branched-chain amino acids in health and disease: metabolism, alterations in blood plasma, and as supplements</h1><div class="half_rhythm" style="margin: 0.6923em 0px;"><div class="contrib-group fm-author"><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Hole%26%23x0010d%3Bek%20M%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=29755574" class="affpopup" co-rid="_co_idm140514528992512" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Milan Hole&#269;ek</a><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;"><img src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fwww.ncbi.nlm.nih.gov%2Fcorehtml%2Fpmc%2Fpmcgifs%2Fcorrauth.gif" alt="corresponding author" style="max-width: 100%; border: 0px;"></span></div></div><div class="fm-panel half_rhythm" style="margin: 0.6923em 0px;"><div class="togglers"><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5934885/#" class="pmctoggle" rid="idm140514519384624_ai" style="color: rgb(100, 42, 143);">Author information</a>&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5934885/#" class="pmctoggle" rid="idm140514519384624_an" style="color: rgb(100, 42, 143);">Article notes</a>&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5934885/#" class="pmctoggle" rid="idm140514519384624_cpl" style="color: rgb(100, 42, 143);">Copyright and License information</a>&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pmc/about/disclaimer/" style="color: rgb(100, 42, 143);">Disclaimer</a></div></div><div id="pmclinksbox" class="links-box whole_rhythm" style="border: 1px solid rgb(234, 195, 175); background-color: rgb(255, 244, 206); padding: 0.3923em 0.6923em; margin: 1.3846em 0px; border-top-left-radius: 5px; border-top-right-radius: 5px; border-bottom-right-radius: 5px; border-bottom-left-radius: 5px;"><div class="fm-panel">This article has been&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5934885/citedby/" style="color: rgb(100, 42, 143);">cited by</a>&nbsp;other articles in PMC.</div></div></div><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 16px; line-height: 21px;"></div><div id="Abs1" lang="en" class="tsec sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 16px; line-height: 21px;"><div class="goto jig-ncbiinpagenav-goto-container" style="float: right; text-align: right; font-family: arial, helvetica, clean, sans-serif; font-size: 0.86666em !important;"><span role="menubar"><a class="tgt_dark page-toc-label jig-ncbiinpagenav-goto-heading" href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5934885/#" title="Go to other sections in this page" role="menuitem" aria-expanded="false" aria-haspopup="true" style="background-image: url(https://static.pubmed.gov/portal/portal3rc.fcgi/4160049/img/2846531); background-color: transparent; padding-right: 17px; margin-right: 3px; color: rgb(100, 42, 143); background-position: 100% 43.5%; background-repeat: no-repeat no-repeat;">Go to:</a></span></div><h2 class="head no_bottom_margin ui-helper-clearfix" id="Abs1title" style="font-size: 1.125em; line-height: 1.1111em; margin: 1.125em 0px 0px; color: rgb(152, 87, 53); min-height: 0px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(151, 176, 200); font-family: arial, helvetica, clean, sans-serif; font-weight: normal;">Abstract</h2><div><p id="Par1" class="p p-first" style="margin-top: 0.6923em; margin-bottom: 0.6923em;"><b><span style="color: rgb(9, 0, 255);">Branched-chain amino acids (BCAAs; valine, leucine, and isoleucine) are essential amino acids with protein anabolic properties, which have been studied in a number of muscle wasting disorders for more than 50&nbsp;years</span></b>. However, until today, there is no consensus regarding their therapeutic effectiveness.</p><p id="Par2" style="margin-top: 0.6923em; margin-bottom: 0.6923em;">In the article is demonstrated that the crucial roles in BCAA metabolism play:&nbsp;</p><p id="Par2" style="margin-top: 0.6923em; margin-bottom: 0.6923em;">(i) <b><span style="color: rgb(255, 0, 0);">skeletal muscle as the initial site of BCAA catabolism accompanied with the release of alanine and glutamine to the blood</span></b>;&nbsp;</p><p id="Par2" style="margin-top: 0.6923em; margin-bottom: 0.6923em;">(ii) <b><span style="color: rgb(255, 0, 0);">activity of branched-chain keto acid dehydrogenase (BCKD)</span></b>; and&nbsp;</p><p id="Par2" style="margin-top: 0.6923em; margin-bottom: 0.6923em;">(iii) <b><span style="color: rgb(255, 0, 0);">amination of branched-chain keto acids (BCKAs) to BCAAs</span></b>.&nbsp;</p><p id="Par2" style="margin-top: 0.6923em; margin-bottom: 0.6923em;"><br></p><p id="Par2" style="margin-top: 0.6923em; margin-bottom: 0.6923em;">Enhanced consumption of BCAA for ammonia detoxification to glutamine in muscles is the cause of decreased BCAA levels in liver cirrhosis and urea cycle disorders. Increased BCKD activity is responsible for enhanced oxidation of BCAA in chronic renal failure, trauma, burn, sepsis, cancer, phenylbutyrate-treated subjects, and during exercise. Decreased BCKD activity is the main cause of increased BCAA levels and BCKAs in maple syrup urine disease, and plays a role in increased BCAA levels in diabetes type 2 and obesity. Increased BCAA concentrations during brief starvation and type 1 diabetes are explained by amination of BCKAs in visceral tissues and decreased uptake of BCAA by muscles.</p><p id="Par3" style="margin-top: 0.6923em; margin-bottom: 0.6923em;">The studies indicate beneficial effects of BCAAs and BCKAs in therapy of chronic renal failure. New therapeutic strategies should be developed to enhance effectiveness and avoid adverse effects of BCAA on ammonia production in subjects with liver cirrhosis and urea cycle disorders. Further studies are needed to elucidate the effects of BCAA supplementation in burn, trauma, sepsis, cancer and exercise. Whether increased BCAA levels only markers are or also contribute to insulin resistance should be known before the decision is taken regarding their suitability in obese subjects and patients with type 2 diabetes.</p><p id="Par4" class="p p-last" style="margin-top: 0.6923em; margin-bottom: 0.6923em;">It is concluded that a<b><span style="color: rgb(255, 0, 0);">lterations in BCAA metabolism have been found common in a number of disease states and careful studies are needed to elucidate their therapeutic effectiveness in most indications</span></b>.</p></div></div><p><strong class="kwd-title" style="color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 16px; line-height: 21px;">Keywords:&nbsp;</strong><span class="kwd-text" style="color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 16px; line-height: 21px;">Cachexia, Ammonia, Glutamine, Diabetes, Cirrhosis, Nutrition</span><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><b>다. 함황 아미노산의 대사<span style="color: rgb(255, 0, 0);">(sulfur amino acid)</span></b></span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(9, 0, 255);">황을 함유한 시스테인은 탈아미노반응 후 피르브산과 황산이 되며 글루타치온이나 타우린의 합성 전구체로서 중요</span></b>함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">메티오닌은 필수아미노산이며 지방간 예방인자</span></b>임. 간에서 5-아데노실메티오닌(활성 메티오닌)이 되며 콜린합성에 관여함.&nbsp;</span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><p><span style="font-size: 15px; line-height: 23px;"><br></span></p><div class="sc-cqCuEk dDomlX article_header_class" style="box-sizing: border-box; padding: 0px;"><p class="sc-ipZHIp hDKZCZ article_type" style="box-sizing: border-box; font-size: 14px; font-weight: 700; line-height: 20px; letter-spacing: 0.58px; margin-top: -4px !important;">Review Article |&nbsp;Open Access</p><div class="sc-iGrrsa eZlme article_citation" style="box-sizing: border-box; font-size: 14px; line-height: 22px;">Volume&nbsp;2017&nbsp;<span class="sc-dEoRIm gusDuS" style="box-sizing: border-box; padding: 0px 3px;">|</span>Article ID&nbsp;9584932&nbsp;<span class="sc-dEoRIm gusDuS" style="box-sizing: border-box; padding: 0px 3px;">|</span>&nbsp;6&nbsp;pages&nbsp;<span class="sc-dEoRIm gusDuS" style="box-sizing: border-box; padding: 0px 3px;">|&nbsp;</span><a class="sc-htpNat bUhGXt link sc-jtggT iUDBGe" href="https://doi.org/10.1155/2017/9584932" aria-label="Doi-link" style="box-sizing: border-box; color: rgb(77, 138, 23); -webkit-text-decoration-line: none; border-top-left-radius: 5px; border-top-right-radius: 5px; border-bottom-right-radius: 5px; border-bottom-left-radius: 5px; cursor: pointer;">https://doi.org/10.1155/2017/9584932</a></div><h1 class="sc-jAaTju cxkaTM sc-bmyXtO jXfovC article_title" style="box-sizing: border-box; font-size: 30px; line-height: 34px; margin: 19px 0px 22px; font-family: STIXGeneral-Bold;">Oxidation Resistance of the Sulfur Amino Acids: <span style="color: rgb(255, 0, 0);">Methionine and Cysteine</span></h1></div><div class="sc-jeCdPy bpzNtR article_authors" style="box-sizing: border-box; padding: 0px; margin: 20px 0px;"><hr class="sc-likbZx PHYWq hr__author" style="box-sizing: border-box; border-style: solid none none; border-top-color: rgb(227, 227, 227); height: 2px; margin: 15px 0px 12px;"><span class="" style="box-sizing: border-box; font-size: 14px;">Peng Bin,<sup style="box-sizing: border-box;">1,2</sup>&nbsp;</span><span class="" style="box-sizing: border-box; font-size: 14px;">Ruilin Huang,<sup style="box-sizing: border-box;">1</sup>&nbsp;and&nbsp;</span><span class="" style="box-sizing: border-box; font-size: 14px;"><b style="box-sizing: border-box;">Xihong Zhou</b><a class="sc-htpNat bUhGXt link" href="mailto:" aria-label="Mail to Author Option" style="box-sizing: border-box; color: rgb(77, 138, 23); -webkit-text-decoration-line: none; border-top-left-radius: 5px; border-top-right-radius: 5px; border-bottom-right-radius: 5px; border-bottom-left-radius: 5px; font-size: 16px; cursor: pointer;"><img alt=" " class="sc-EHOje cPuqxU sc-jtRlXQ jIaDFG" title="" role="presentation" src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fstatic-01.hindawi.com%2Fnext_assets%2FgURqCOtzm7YVbiMy1K3bP%2F_next%2Fstatic%2Fnode_modules%2Fhindawi-ui%2Fsrc%2Ficon%2Fsvg%2FsocialMail.svg" height="16" style="box-sizing: border-box; vertical-align: middle; height: 16px; width: 16px; margin: 0px 2px 2px;"></a><a class="sc-htpNat bUhGXt link" href="http://orcid.org/0000-0002-0007-3504" aria-label="Redirect to Doi" target="_blank" style="box-sizing: border-box; color: rgb(77, 138, 23); -webkit-text-decoration-line: none; border-top-left-radius: 5px; border-top-right-radius: 5px; border-bottom-right-radius: 5px; border-bottom-left-radius: 5px; font-size: 16px; cursor: pointer;"><img alt=" " class="sc-EHOje cPuqxU sc-bGbJRg flqdYJ" title="" role="presentation" src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fstatic-01.hindawi.com%2Fnext_assets%2FgURqCOtzm7YVbiMy1K3bP%2F_next%2Fstatic%2Fnode_modules%2Fhindawi-ui%2Fsrc%2Ficon%2Fsvg%2Fdoi.svg" height="16" style="box-sizing: border-box; vertical-align: middle; height: 16px; width: 16px; margin-bottom: 2px;"></a><sup style="box-sizing: border-box;">1</sup></span><div class="sc-ePZHVD eGAJYa isHide" style="box-sizing: border-box; overflow-y: hidden; height: auto; max-height: 0px; transition: all 0.5s; -webkit-transition: all 0.5s;"><p style="box-sizing: border-box; font-size: 14px; line-height: 20px; display: -webkit-flex; margin-top: 15px; margin-bottom: 12px;"><sup style="box-sizing: border-box; margin-top: -5px;"></sup></p><p style="box-sizing: border-box; font-size: 14px; line-height: 20px; display: -webkit-flex; margin-top: 12px; margin-bottom: 12px;"><sup style="box-sizing: border-box; margin-top: -5px;"></sup></p></div><button class="sc-kEYyzF gRIXYh sc-bEjcJn cFrLKZ" color="" style="cursor: pointer; display: -webkit-flex; background-color: rgb(255, 255, 255); color: rgb(77, 138, 23); width: auto; border-top-left-radius: 5px; border-top-right-radius: 5px; border-bottom-right-radius: 5px; border-bottom-left-radius: 5px; font-size: 12px; font-family: 'IBM Plex Sans', sans-serif; margin-top: 5px; -webkit-text-decoration-line: none;">Show more</button></div><div class="articleContent__EditorWrapper-sc-2yl9jy-3 evMkvU" style="box-sizing: border-box; padding: 0px;"><div class="articleContent__TextWrapper-sc-2yl9jy-8 fYrLtk" style="box-sizing: border-box; margin: -7px 0px -5px; font-size: 14px;"><b style="box-sizing: border-box;">Academic Editor:&nbsp;</b>Lidong Zhai</div><div class="articleContent__PublicationTimeLineWrapper-sc-2yl9jy-4 fjviok" style="box-sizing: border-box; display: -webkit-flex; -webkit-flex-wrap: wrap; margin: 20px 0px 30px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(227, 227, 227); border-top-width: 1px; border-top-style: solid; border-top-color: rgb(227, 227, 227);"><div class="articleContent__PublcationCol-sc-2yl9jy-5 hgKieC notPublished" style="box-sizing: border-box; -webkit-flex-basis: 0px; -webkit-box-flex: 1; -webkit-flex-grow: 1; max-width: 100%; border-right-width: 1px; border-right-style: solid; border-right-color: rgb(227, 227, 227); padding: 5px 0px;"><span class="articleContent__PublicationField-sc-2yl9jy-6 cIribm" style="box-sizing: border-box; display: block; text-align: center; font-size: 14px; font-weight: 700;">Received</span><span class="articleContent__PublicationValue-sc-2yl9jy-7 khHUcu" style="box-sizing: border-box; display: block; text-align: center; font-size: 14px;">12 Sep 2017</span></div><div class="articleContent__PublcationCol-sc-2yl9jy-5 hgKieC notPublished" style="box-sizing: border-box; -webkit-flex-basis: 0px; -webkit-box-flex: 1; -webkit-flex-grow: 1; max-width: 100%; border-right-width: 1px; border-right-style: solid; border-right-color: rgb(227, 227, 227); padding: 5px 0px;"><span class="articleContent__PublicationField-sc-2yl9jy-6 cIribm" style="box-sizing: border-box; display: block; text-align: center; font-size: 14px; font-weight: 700;">Accepted</span><span class="articleContent__PublicationValue-sc-2yl9jy-7 khHUcu" style="box-sizing: border-box; display: block; text-align: center; font-size: 14px;">20 Nov 2017</span></div><div class="articleContent__PublcationCol-sc-2yl9jy-5 hgKieC isPublished" style="box-sizing: border-box; -webkit-flex-basis: 0px; -webkit-box-flex: 1; -webkit-flex-grow: 1; max-width: 100%; border-right-style: none; padding: 5px 0px;"><span class="articleContent__PublicationField-sc-2yl9jy-6 cIribm" style="box-sizing: border-box; display: block; text-align: center; font-size: 14px; font-weight: 700;">Published</span><span class="articleContent__PublicationValue-sc-2yl9jy-7 khHUcu" style="box-sizing: border-box; display: block; text-align: center; font-size: 14px;">27 Dec 2017</span></div></div></div><article class="sc-kZmsYB dPAEQd article_body " style="box-sizing: border-box; text-align: justify; margin-bottom: 100px; padding: 0px;"><div style="box-sizing: border-box;"><div class="xml-content" style="box-sizing: border-box;"><h4 class="header" id="abstract" style="font-family: 'IBM Plex Sans', sans-serif; box-sizing: border-box; font-size: 20px; border-top-width: 0px; border-top-style: solid; border-top-color: rgb(227, 227, 227); padding-top: 0px; margin-top: 34px; margin-bottom: -3px; color: rgb(0, 0, 0);">Abstract</h4><p style="font-family: STIXGeneral-Regular; box-sizing: border-box; font-size: 16px; word-break: break-word; margin-top: 12px; margin-bottom: 12px; line-height: 20px; color: rgb(0, 0, 0);"><b><span style="color: rgb(255, 0, 0);">Sulfur amino acids are a kind of amino acids which contain sulfhydryl, and they play a crucial role in protein structure, metabolism, immunity, and oxidation</span></b>. Our review demonstrates the oxidation resistance effect of methionine and cysteine, two of the most representative sulfur amino acids, and their metabolites. Methionine and cysteine are extremely sensitive to almost all forms of reactive oxygen species, which makes them antioxidative. <b><span style="color: rgb(9, 0, 255);">Moreover, methionine and cysteine are precursors of S-adenosylmethionine, hydrogen sulfide, taurine, and glutathione. These products are reported to alleviate oxidant stress induced by various oxidants and protect the tissue from the damage.</span></b> However, the deficiency and excess of methionine and cysteine in diet affect the normal growth of animals; thereby a new study about defining adequate levels of methionine and cysteine intake is important.</p><p style="font-family: STIXGeneral-Regular; box-sizing: border-box; font-size: 16px; word-break: break-word; margin-top: 12px; margin-bottom: 12px; line-height: 20px; color: rgb(0, 0, 0);"><br></p><h1 style="font-size: 1.4em; margin: 0.5em 0px; line-height: 1.25em; color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif; orphans: 2; text-align: left; widows: 2; background-color: rgb(255, 255, 255);">The sulfur-containing amino acids: an overview.</h1><div class="auths" style="font-size: 0.923em; color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif; orphans: 2; text-align: left; widows: 2; background-color: rgb(255, 255, 255);"><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Brosnan%20JT%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=16702333" style="color: rgb(102, 0, 102); border-bottom: 0px; text-decoration: underline;">Brosnan JT</a><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">1</span>,&nbsp;<a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Brosnan%20ME%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=16702333" style="color: rgb(102, 0, 102); border-bottom: 0px; text-decoration: underline;">Brosnan ME</a>.</div><div class="afflist" style="color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif; font-size: 13px; orphans: 2; text-align: left; widows: 2; background-color: rgb(255, 255, 255); zoom: 1;"><h3 style="font-size: 1.0769em; line-height: 1.2857; margin: 0.5em 0em; color: rgb(114, 65, 40); zoom: 1;"><a title="Open/close author information list" class="jig-ncbitoggler ui-widget ui-ncbitoggler" href="https://www.ncbi.nlm.nih.gov/pubmed/16702333#" id="ui-ncbitoggler-2" role="button" aria-expanded="false" style="font-size: 13.9997px; color: rgb(102, 0, 102); padding-left: 16px; position: relative; display: block; border-bottom-width: 0px; outline: none; font-family: arial, sans-serif !important;"><span class="ui-ncbitoggler-master-text">Author information</span><span class="ui-icon ui-icon-triangle-1-e" style="display: inline; text-indent: -99999px; overflow: hidden; background: url(&quot;//static.pubmed.gov/portal/portal3rc.fcgi/4188898/img/3974597&quot;) 0px -21px no-repeat scroll transparent; width: 16px; height: 16px; position: absolute; left: 0px; border: none; border-bottom-left-radius: 3px; border-bottom-right-radius: 3px; margin: 0px; padding: 0px; right: 0px; top: 0px;"></span></a></h3><div class="ui-helper-reset" aria-live="assertive" style="margin: 0px; padding: 0px; border: 0px; outline: 0px; line-height: 1.3; list-style: none;"></div></div><div class="abstr" style="line-height: 1.538em; margin: 1.2em auto auto; color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif; font-size: 13px; orphans: 2; text-align: left; widows: 2; background-color: rgb(255, 255, 255);"><h3 style="font-size: 1.0769em; line-height: 1.2857; margin: 0px; color: rgb(152, 87, 53); display: inline;">Abstract</h3><div class=""><p style="margin-bottom: 0.5em; font-size: 1.04em;"><b><span style="color: rgb(255, 0, 0);">Methionine, cysteine, homocysteine, and taurine are the 4 common sulfur-containing amino acids,</span></b> but only the first 2 are incorporated into proteins. Sulfur belongs to the same group in the periodic table as oxygen but is much less electronegative. This difference accounts for some of the distinctive properties of the sulfur-containing amino acids.&nbsp;</p><p style="margin-bottom: 0.5em; font-size: 1.04em;"><br></p><p style="margin-bottom: 0.5em; font-size: 1.04em;"><b><span style="color: rgb(0, 85, 255);">Methionine is the initiating amino acid in the synthesis of virtually all eukaryotic proteins</span></b>; N-formylmethionine serves the same function in prokaryotes. Within proteins, many of the methionine residues are buried in the hydrophobic core, but some, which are exposed, are susceptible to oxidative damage.&nbsp;</p><p style="margin-bottom: 0.5em; font-size: 1.04em;"><b><span style="color: rgb(0, 85, 255);">Cysteine, by virtue of its ability to form disulfide bonds, plays a crucial role in protein structure and in protein-folding pathways.</span></b> Methionine metabolism begins with its activation to S-adenosylmethionine. This is a cofactor of extraordinary versatility, playing roles in methyl group transfer, 5'-deoxyadenosyl group transfer, polyamine synthesis, ethylene synthesis in plants, and many others. In animals, the great bulk of S-adenosylmethionine is used in methylation reactions. S-Adenosylhomocysteine, which is a product of these methyltransferases, gives rise to homocysteine.&nbsp;</p><p style="margin-bottom: 0.5em; font-size: 1.04em;"><b><span style="color: rgb(0, 85, 255);">Homocysteine may be remethylated to methionine or converted to cysteine by the transsulfuration pathwa</span></b>y. Methionine may also be metabolized by a transamination pathway. This pathway, which is significant only at high methionine concentrations, produces a number of toxic end products.&nbsp;</p><p style="margin-bottom: 0.5em; font-size: 1.04em;">Cysteine may be converted to such important products as glutathione and taurine. <b><span style="color: rgb(0, 85, 255);">Taurine is present in many tissues at higher concentrations than any of the other amino acids. It is an essential nutrient for cats</span></b>.</p></div></div><div style="font-family: STIXGeneral-Regular;"><br></div><div><p style="font-family: STIXGeneral-Regular; text-align: center;"></p><p style="font-family: STIXGeneral-Regular;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;"><b>라. 지방족 아미노산(aliphatic amino acid)의 대사</b></span><br></p><p style="font-family: STIXGeneral-Regular;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;"><b><span style="color: rgb(255, 0, 0);">세린과 트레오닌은 당단백질 중 당의 사슬과 단백질과의 결합을 하고 있는 아미노산으로 작용</span></b>함. 세린은 피르브산의 모양으로 트레오닌은 프로피온산 혹은 아세틸 &nbsp;CoA의 형태로 시트르산 회로로 들어감. 이 두 아미노산은 글리신의 생합성 재료로도 중요함.&nbsp;</span></p><p style="font-family: STIXGeneral-Regular;"><span style="font-family: Batang, 바탕, serif; font-size: 11pt;"><br></span></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><b>마. 방향족 아미노산의 대사</b></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(255, 0, 0);">방향족 고리를 포함하는 아미노산으로 20개의 아미노산중 페닐알라닌, 트립토판, 티로신, 히스티틴 등이 방향족 아미노산</span></b>임.&nbsp;페닐알라닌은 푸마르산, 아세트산으로 분해되며 티로신, 멜라닌, 아드레날린(부신피질 호르몬)등의 전구체로서 중요함. 페닐알라닌은 산화되어 티로신이 됨. 이 과정에 관여하는 효소가 결핍되면 페닐케톤뇨증이 됨. 페닐알라닌은 페닐피르브산이 되고 다시 분해되어 푸마르산이 되어 시트르산 회로로 들어감. 백피증은 페닐알라닌 대사이상으로 멜라닌 합성 대사경로의 효소결핍에 의한 질병이며 사람과 동물에서 나타남.&nbsp;</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">그림) 방향족 아미노산의 대사</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(9, 0, 255);">트립토판은 필수 아미노산이며 트립토판에서 세로토닌, 멜라토닌과 니코틴산 등이 합성</span></b>됨.&nbsp;</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">트립토판 대사</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><b>5) 단백질 합성</b></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">단백질 합성은 매우 효율적이고 연령에 따라 다름. 단백질 섭취량 당 합성량은 영아 5.3g, 성인 5.2g, 노인 4.5g임.&nbsp;</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><b>가. 단백질 합성과 아미노산</b></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><b><span style="color: rgb(9, 0, 255);">아미노산은 세포와 조직에서 필요한 특정 단백질을 간에서 합성하기 위해 인체의 각 부분으로 이동</span></b>됨. 필수 아미노산뿐만 아니라 비필수 아미노산도 단백질을 합성하기 위해 반드시 필요함<b><span style="color: rgb(255, 0, 0);">. 단백질 합성에 필요한 모든 종류의 필수 아미노산은 반드시 각 조직에 공급되어야 함. 만약 필수 아미노산이 부족하면 단백질 합성이 일어나지 않음</span></b>. 또한 특정 단백질 합성에 필요한 비필수 아미노산은 혈액에서 세포로 직접 공급되기도 하고 혹은 혈액에서 즉각 이용되지 못한다하더라도 세포에서 합성이 가능함. 이러한 <b><span style="color: rgb(0, 85, 255);">비필수 아미노산의 형성은 아미노기 전이반응과정과 더불어 발생</span></b>함. 가장 간단한 형태는 한 아미노산의 아미노기를 적당한 비질소 화합물에 이동시켜 아미노산을 합성하는 것임. <b><span style="color: rgb(0, 85, 255);">피리독신(vitamin B6)은 아미노기 전이반응을 돕는 비타민</span></b>임.&nbsp;</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p></p><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: &quot;Times New Roman&quot;, stixgeneral, serif; font-size: 15.9991px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial;"></div><div id="idm139847166922928" lang="en" class="tsec sec" style="clear: both; display: none; color: rgb(0, 0, 0); font-family: &quot;Times New Roman&quot;, stixgeneral, serif; font-size: 15.9991px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial;"><div class="goto jig-ncbiinpagenav-goto-container" style="float: right; text-align: right; font-family: arial, helvetica, clean, sans-serif; font-size: 0.86666em !important;"><span role="menubar"><a class="tgt_dark page-toc-label jig-ncbiinpagenav-goto-heading" href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5372852/#" title="Go to other sections in this page" role="menuitem" aria-expanded="false" aria-haspopup="true" style="background: url(&quot;//static.pubmed.gov/portal/portal3rc.fcgi/4160049/img/2846531&quot;) 100% 43.5% no-repeat transparent; padding-right: 17px; margin-right: 3px; text-decoration: none; color: rgb(100, 42, 143);">Go to:</a></span></div><h2 class="head no_bottom_margin ui-helper-clearfix" id="idm139847166922928title" style="font-size: 1.125em; line-height: 1.1111em; margin: 1.125em 0px 0px; color: rgb(152, 87, 53); min-height: 0px; display: block; border-bottom: 1px solid rgb(151, 176, 200); font-family: arial, helvetica, clean, sans-serif; font-weight: normal;">Abstract</h2><div><p id="__p1" class="p p-first-last" style="margin: 0.6923em 0px;">Vitamin B<sub style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;">6</sub><span>&nbsp;</span>(B<sub style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;">6</sub>) has a central role in the metabolism of amino acids, which includes important interactions with endogenous redox reactions through its effects on the glutathione peroxidase (GPX) system. In fact, B<sub style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;">6</sub>-dependent enzymes catalyse most reactions of the transsulfuration pathway, driving homocysteine to cysteine and further into GPX proteins. Considering that mammals metabolize sulfur- and seleno-amino acids similarly, B<sub style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;">6</sub><span>&nbsp;</span>plays an important role in the fate of sulfur-homocysteine and its seleno counterpart between transsulfuration and one-carbon metabolism, especially under oxidative stress conditions. This is particularly important in reproduction because ovarian metabolism may generate an excess of reactive oxygen species (ROS) during the peri-estrus period, which may impair ovulatory functions and early embryo development. Later in gestation, placentation raises embryo oxygen tension and may induce a higher expression&#8206; of ROS markers and eventually embryo losses. Interestingly, the metabolic accumulation of ROS up-regulates the flow of one-carbon units to transsulfuration and down-regulates remethylation. However, in embryos, the transsulfuration pathway is not functional, making the understanding of the interplay between these two pathways particularly crucial. In this review, the importance of the maternal metabolic status of B<sub style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;">6</sub><span>&nbsp;</span>for the flow of one-carbon units towards both maternal and embryonic GPX systems is discussed. Additionally, B<sub style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;">6</sub><span>&nbsp;</span></p></div></div><p></p><div class="fm-sec half_rhythm no_top_margin" style="margin: 0px 0px 0.6923em; font-style: normal; font-variant: normal; font-size: 0.8425em; line-height: 1.6363em; font-family: arial, helvetica, clean, sans-serif; color: rgb(0, 0, 0); letter-spacing: normal; orphans: 2; text-align: left; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255);"><h1 class="content-title" style="font-size: 1.5384em; margin: 1em 0px 0.5em; line-height: 1.35em; color: rgb(0, 0, 0); font-family: arial, helvetica, clean, sans-serif;"><span style="color: rgb(255, 0, 0);">Pyridoxine (Vitamin B</span><sub style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;"><span style="color: rgb(255, 0, 0);">6</span></sub><span style="color: rgb(255, 0, 0);">) and the Glutathione Peroxidase System</span><span style="font-weight: normal;">; a Link between One-Carbon Metabolism and Antioxidation</span></h1><div class="half_rhythm" style="font-weight: 400; margin: 0.6923em 0px;"><div class="contrib-group fm-author"><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Dalto%20DB%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=28245568" class="affpopup" co-rid="_co_idm139847128145888" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Danyel Bueno Dalto</a><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">1,</sup><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">2</sup><span>&nbsp;</span>and<span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pubmed/?term=Matte%20JJ%5BAuthor%5D&amp;cauthor=true&amp;cauthor_uid=28245568" class="affpopup" co-rid="_co_idm139847129124176" co-class="co-affbox" style="white-space: nowrap; color: rgb(100, 42, 143);">Jean-Jacques Matte</a><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">1,</sup><sup style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; top: -0.5em;">*</sup></div></div><div class="fm-panel half_rhythm" style="font-weight: 400; margin: 0.6923em 0px;"><div class="togglers"><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5372852/#" class="pmctoggle" rid="idm139847202121296_ai" style="text-decoration: none; color: rgb(100, 42, 143);">Author information</a><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5372852/#" class="pmctoggle" rid="idm139847202121296_an" style="text-decoration: none; color: rgb(100, 42, 143);">Article notes</a><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5372852/#" class="pmctoggle" rid="idm139847202121296_cpl" style="text-decoration: none; color: rgb(100, 42, 143);">Copyright and License information</a><span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/about/disclaimer/" style="color: rgb(100, 42, 143);">Disclaimer</a></div></div><div id="pmclinksbox" class="links-box whole_rhythm" style="font-weight: 400; border: 1px solid rgb(234, 195, 175); background-color: rgb(255, 244, 206); padding: 0.3923em 0.6923em; margin: 1.3846em 0px; border-top-left-radius: 5px; border-top-right-radius: 5px; border-bottom-right-radius: 5px; border-bottom-left-radius: 5px;"><div class="fm-panel"><div>This article has been<span>&nbsp;</span><a href="https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5372852/citedby/" style="color: rgb(100, 42, 143);">cited by</a><span>&nbsp;</span>other articles in PMC.</div></div></div></div><h2 class="head no_bottom_margin ui-helper-clearfix" id="idm139847166922928title" style="font-size: 1.125em; line-height: 1.1111em; margin: 1.125em 0px 0px; color: rgb(152, 87, 53); min-height: 0px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(151, 176, 200); font-family: arial, helvetica, clean, sans-serif; font-weight: normal; orphans: 2; text-align: left; widows: 2; background-color: rgb(255, 255, 255);">Abstract</h2><div style="color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 15.9991px; orphans: 2; text-align: left; widows: 2; background-color: rgb(255, 255, 255);"><p id="__p1" class="p p-first-last" style="margin-top: 0.6923em; margin-bottom: 0.6923em;"><b><span style="color: rgb(255, 0, 0);">Vitamin B</span><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em; color: rgb(255, 0, 0);">6</span><span style="color: rgb(255, 0, 0);">&nbsp;</span><span style="color: rgb(255, 0, 0);">(B</span><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em; color: rgb(255, 0, 0);">6</span><span style="color: rgb(255, 0, 0);">) has a central role in the metabolism of amino acids, which includes important interactions with endogenous redox reactions through its effects on the glutathione peroxidase (GPX) system</span></b>. In fact, B<span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;">6</span>-dependent enzymes catalyse most reactions of the transsulfuration pathway, driving homocysteine to cysteine and further into GPX proteins.<b><span style="color: rgb(9, 0, 255);"> Considering that mammals metabolize sulfur- and seleno-amino acids similarly, B</span><span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em; color: rgb(9, 0, 255);">6</span><span style="color: rgb(9, 0, 255);">&nbsp;plays an important role in the fate of sulfur-homocysteine and its seleno counterpart between transsulfuration and one-carbon metabolism, especially under oxidative stress conditions</span></b>. This is particularly important in reproduction because ovarian metabolism may generate an excess of reactive oxygen species (ROS) during the peri-estrus period, which may impair ovulatory functions and early embryo development. Later in gestation, placentation raises embryo oxygen tension and may induce a higher expression&#8206; of ROS markers and eventually embryo losses. Interestingly, the metabolic accumulation of ROS up-regulates the flow of one-carbon units to transsulfuration and down-regulates remethylation. However, in embryos, the transsulfuration pathway is not functional, making the understanding of the interplay between these two pathways particularly crucial. In this review, the importance of the maternal metabolic status of B<span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;">6</span>&nbsp;for the flow of one-carbon units towards both maternal and embryonic GPX systems is discussed. Additionally, B<span style="font-size: 0.8461em; line-height: 1.6363em; position: relative; vertical-align: baseline; bottom: -0.25em; top: 0.25em;">6</span>&nbsp;effects on GPX activity and gene expression&#8206; in dams, as well as embryo development, are presented in a pig model under different oxidative stress conditions.</p></div><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 15.9991px; orphans: 2; text-align: left; widows: 2; background-color: rgb(255, 255, 255);"><strong class="kwd-title">Keywords:&nbsp;</strong><span class="kwd-text">glutathione peroxidase, one-carbon, pig, pyridoxine, remethylation, transsulfuration</span></div><div class="sec" style="clear: both; color: rgb(0, 0, 0); font-family: 'Times New Roman', stixgeneral, serif; font-size: 15.9991px; orphans: 2; text-align: left; widows: 2; background-color: rgb(255, 255, 255);"><span class="kwd-text"><br></span></div><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">2) 단백질 합성과정</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">단백질은 복잡한 메커니즘에 의해 합성됨. <b><span style="color: rgb(255, 0, 0);">단백질 합성에서 아미노산의 종류와 배합순서를 나타내는 유전정보는 DNA의 코드에 따라 전달</span></b>됨. 실제 <b><span style="color: rgb(9, 0, 255);">단백질 합성장소는 세포내의 리보솜이며 정보전달물질인 DNA에서 명시된 단백질이 합성</span></b>되도록 함.&nbsp;</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">단백질 합성을 단순화하면 다음 세 과정으로 구분할 수 있음.&nbsp;</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">1단계 : DNA에서 세개의 염기로 된 코드그룹들이 각 아미노산을 합성하는 신호</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">2단계 : mRNA는 핵속 DNA에서 이 아미노산 코드가 전사되는 세포질로 운반</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">3단계 : mRNA는 리보솜에 부착하여 tRNA가 가지고 온 아미노산을 일렬로 연결하여 주므로 단백질이 합성됨.&nbsp;</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;">단백질 합성을 알기 쉽게 컴퓨터 자판으로 연상해 그림으로 나타낼 수 있음. 자판 세개가 한 아미노산이며 자판 세개를 치는 것은 여러가지 아미노산을 지칭함. 세개의 일정한 자판을 두드리면 아미노산의 순서가 정해지는데 이것은 mRNA때문임. 그러면 부호를 전달하여 움직여 주며 이 아미노산이 연결되어 단백질이 합성됨. 만약 페닐알라닌을 자판(코드)으로 부를때 롤러의 끝에 이 아미노산이 없으면 합성은 중지됨. 즉 필수아미노산과 비필수 아미노산 모두가 충분히 공급되어야만 체내에 필요한 단백질 합성이 가능함. 그러므로 영양소로서 아미노산과 단백질의 섭취가 중요함</span></font></p><p><font face="Batang, 바탕, serif"><span style="font-size: 15px; line-height: 23px;"><br></span></font></p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);"><b>Protein biosynthesis</b>&nbsp;(or&nbsp;<b>protein synthesis</b>) is a core biological process, occurring inside&nbsp;<a href="https://en.wikipedia.org/wiki/Cell_(biology)" title="Cell (biology)" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">cells</a>, which&nbsp;<a href="https://en.wikipedia.org/wiki/Homeostasis" title="Homeostasis" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">balances</a>&nbsp;the loss of cellular&nbsp;<a href="https://en.wikipedia.org/wiki/Protein" title="Protein" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">proteins</a>&nbsp;(via&nbsp;<a href="https://en.wikipedia.org/wiki/Proteolysis" title="Proteolysis" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">degradation</a>&nbsp;or&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_targeting" title="Protein targeting" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">export</a>) through the production of new proteins. Proteins perform a variety of critical functions as&nbsp;<a href="https://en.wikipedia.org/wiki/Enzyme" title="Enzyme" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">enzymes</a>, structural proteins or&nbsp;<a href="https://en.wikipedia.org/wiki/Hormone" title="Hormone" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">hormones</a>&nbsp;and therefore, are crucial biological components. As a result, protein synthesis is regulated at multiple steps&nbsp;<sup id="cite_ref-Alberts_2015_1-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Alberts_2015-1" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[1]</a></sup>. Protein synthesis is very similar for&nbsp;<a href="https://en.wikipedia.org/wiki/Prokaryote" title="Prokaryote" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">prokaryotes</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/Eukaryote" title="Eukaryote" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">eukaryotes</a>&nbsp;but there are distinct differences.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Protein synthesis can be divided broadly into two phases -&nbsp;<a href="https://en.wikipedia.org/wiki/Transcription_(biology)" title="Transcription (biology)" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">transcription</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/Translation_(biology)" title="Translation (biology)" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">translation</a>. During transcription, a&nbsp;<a href="https://en.wikipedia.org/wiki/Gene" title="Gene" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">gene</a>&nbsp;(section of&nbsp;<a href="https://en.wikipedia.org/wiki/DNA" title="DNA" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">DNA</a>) is converted into a template molecule (<a href="https://en.wikipedia.org/wiki/Messenger_RNA" title="Messenger RNA" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">messenger RNA</a>) by enzymes, known as&nbsp;<a href="https://en.wikipedia.org/wiki/RNA_polymerases" class="mw-redirect" title="RNA polymerases" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">RNA polymerases</a>, in the nucleus of the cell&nbsp;<sup id="cite_ref-O'Connor_2010_2-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-O'Connor_2010-2" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[2]</a></sup>. This mRNA is exported from the&nbsp;<a href="https://en.wikipedia.org/wiki/Cell_nucleus" title="Cell nucleus" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">nucleus</a>&nbsp;via&nbsp;<a href="https://en.wikipedia.org/wiki/Nuclear_pore" title="Nuclear pore" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">nuclear pores</a>&nbsp;to the&nbsp;<a href="https://en.wikipedia.org/wiki/Cytoplasm" title="Cytoplasm" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">cytoplasm</a>&nbsp;of the cell for translation to occur. Subsequently during translation, the messenger RNA is read by&nbsp;<a href="https://en.wikipedia.org/wiki/Ribosome" title="Ribosome" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">ribosomes</a>&nbsp;in the cytoplasm and the&nbsp;<a href="https://en.wikipedia.org/wiki/Nucleotide" title="Nucleotide" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">nucleotide</a>&nbsp;sequence of the mRNA is used to determine the sequence of&nbsp;<a href="https://en.wikipedia.org/wiki/Amino_acid" title="Amino acid" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">amino acids</a>. The amino acids are joined together by&nbsp;<a href="https://en.wikipedia.org/wiki/Peptide_bond" title="Peptide bond" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">peptide bonds</a>&nbsp;(a type of&nbsp;<a href="https://en.wikipedia.org/wiki/Covalent_bond" title="Covalent bond" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">covalent bond</a>) to form a polypeptide chain.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Following translation of the mRNA into a polypeptide chain, this polypeptide chain must fold to form a functional protein i.e. fold to produce the functional&nbsp;<a href="https://en.wikipedia.org/wiki/Active_site" title="Active site" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">active site</a>&nbsp;of the enzyme. The incorrect folding of polypeptide chains can result in non-functional proteins, this is often caused by&nbsp;<a href="https://en.wikipedia.org/wiki/Mutations" class="mw-redirect" title="Mutations" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">mutations</a>&nbsp;in the underlying DNA&nbsp;<a href="https://en.wikipedia.org/wiki/Nucleotide" title="Nucleotide" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">nucleotide</a>&nbsp;sequence. These mutations in the DNA change the subsequent mRNA sequence, which then changes the amino acid sequence in the polypeptide chain. These mutations can cause the mRNA sequence to be shorter due to&nbsp;<a href="https://en.wikipedia.org/wiki/Stop_codon" title="Stop codon" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">earlier termination of transcription</a>, thereby, producing a shorter polypeptide chain. Alternatively, the mutation can just&nbsp;<a href="https://en.wikipedia.org/w/index.php?title=Change_the_amino_acid_at_that_position&amp;action=edit&amp;redlink=1" class="new" title="Change the amino acid at that position (page does not exist)" style="color: rgb(165, 88, 88); background-image: none; background-position: initial initial; background-repeat: initial initial;">missense mutation</a>&nbsp;in the polypeptide chain&nbsp;<sup id="cite_ref-Scheper_2008_3-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Scheper_2008-3" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[3]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">A correctly folded protein may undergo further maturation through the addition of different&nbsp;<a href="https://en.wikipedia.org/wiki/Post-translational_modification" title="Post-translational modification" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">post-translational modifications</a>, which can alter the proteins ability to function, where the protein is located within the cell (e.g. cytoplasm or nucleus) and the proteins ability to&nbsp;<a href="https://en.wikipedia.org/wiki/Protein-protein_interaction" class="mw-redirect" title="Protein-protein interaction" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">interact with other proteins</a>&nbsp;<sup id="cite_ref-" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[4]</a></sup>&nbsp;.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);"><br></p><div id="toc" class="toc" role="navigation" aria-labelledby="mw-toc-heading" style="border: 1px solid rgb(162, 169, 177); background-color: rgb(248, 249, 250); padding: 7px; font-size: 13.3px; display: table; color: rgb(34, 34, 34); font-family: sans-serif; orphans: 2; text-align: start; widows: 2;"><input type="checkbox" role="button" id="toctogglecheckbox" class="toctogglecheckbox" style="direction: ltr; position: absolute; opacity: 0; z-index: -1; display: none;"><div class="toctitle" lang="en" dir="ltr" style="text-align: center; direction: ltr;"><h2 id="mw-toc-heading" style="color: rgb(0, 0, 0); background-image: none; margin: 1em 0px 0.25em; overflow: hidden; padding: 0px; border: 0px; font-size: 13.3px; line-height: 1.3; display: inline; background-position: initial initial; background-repeat: initial initial;">Contents</h2><span class="toctogglespan" style="font-size: 12.502px;"><label class="toctogglelabel" for="toctogglecheckbox" style="cursor: pointer; color: rgb(6, 69, 173);"></label></span></div><ul style="list-style-image: none; margin-top: 0.3em; margin-right: 0px; margin-bottom: 0.3em; padding: 0px; list-style-type: none;"><li class="toclevel-1 tocsection-1" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Transcription" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">1</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Transcription</span></a><ul style="list-style-image: none; margin: 0px 0px 0px 2em; padding: 0px; list-style-type: none;"><li class="toclevel-2 tocsection-2" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Post-transcriptional_modification" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">1.1</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Post-transcriptional modification</span></a></li></ul></li><li class="toclevel-1 tocsection-3" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Translation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">2</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Translation</span></a></li><li class="toclevel-1 tocsection-4" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Protein_Folding" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">3</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Protein Folding</span></a><ul style="list-style-image: none; margin: 0px 0px 0px 2em; padding: 0px; list-style-type: none;"><li class="toclevel-2 tocsection-5" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Role_of_Protein_Synthesis_in_Disease" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">3.1</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Role of Protein Synthesis in Disease</span></a></li></ul></li><li class="toclevel-1 tocsection-6" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Post-translational_modifications" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">4</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Post-translational modifications</span></a><ul style="list-style-image: none; margin: 0px 0px 0px 2em; padding: 0px; list-style-type: none;"><li class="toclevel-2 tocsection-7" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Cleavage" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">4.1</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Cleavage</span></a></li><li class="toclevel-2 tocsection-8" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Addition_of_chemical_groups" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">4.2</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Addition of chemical groups</span></a></li><li class="toclevel-2 tocsection-9" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Addition_of_complex_molecules" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">4.3</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Addition of complex molecules</span></a></li><li class="toclevel-2 tocsection-10" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#Formation_of_covalent_bonds" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">4.4</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">Formation of covalent bonds</span></a></li></ul></li><li class="toclevel-1 tocsection-11" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#See_also" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">5</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">See also</span></a></li><li class="toclevel-1 tocsection-12" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#References" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">6</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">References</span></a></li><li class="toclevel-1 tocsection-13" style="margin-bottom: 0.1em;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#External_links" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span class="tocnumber" style="display: table-cell; text-decoration: inherit; padding-left: 0px; padding-right: 0.5em; color: rgb(34, 34, 34);">7</span><span class="toctext" style="display: table-cell; text-decoration: inherit;">External links</span></a></li></ul></div><h2 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); font-weight: normal; margin: 1em 0px 0.25em; overflow: hidden; padding: 0px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(162, 169, 177); font-family: 'Linux Libertine', Georgia, Times, serif; line-height: 1.3; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Transcription">Transcription</span><span class="mw-editsection" style="font-family: sans-serif; font-size:10pt; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=1" title="Edit section: Transcription" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h2><div role="note" class="hatnote navigation-not-searchable" style="font-style: italic; padding-left: 1.6em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Main article:&nbsp;<a href="https://en.wikipedia.org/wiki/Transcription_(genetics)" class="mw-redirect" title="Transcription (genetics)" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">Transcription (genetics)</a></div><div class="thumb tright" style="margin: 0.5em 0px 1.3em 1.4em; width: auto; background-color: rgb(255, 255, 255); clear: right; float: right; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2;"><div class="thumbinner" style="min-width: 100px; border: 1px solid rgb(200, 204, 209); padding: 3px; background-color: rgb(248, 249, 250); font-size: 13.16px; text-align: center; overflow: hidden; width: 402px;"><a href="https://en.wikipedia.org/wiki/File:RNA_polymerase_transcribing_template_strand_DNA.png" class="image" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><img alt="" src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2Fthumb%2Fd%2Fdc%2FRNA_polymerase_transcribing_template_strand_DNA.png%2F400px-RNA_polymerase_transcribing_template_strand_DNA.png" decoding="async" width="400" height="232" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/dc/RNA_polymerase_transcribing_template_strand_DNA.png/600px-RNA_polymerase_transcribing_template_strand_DNA.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/dc/RNA_polymerase_transcribing_template_strand_DNA.png/800px-RNA_polymerase_transcribing_template_strand_DNA.png 2x" data-file-width="1648" data-file-height="956" style="border: 1px solid rgb(200, 204, 209); vertical-align: middle; background-color: rgb(255, 255, 255);"></a><div class="thumbcaption" style="border: 0px; line-height: 1.4em; padding: 3px; font-size: 12.3704px; text-align: left;"><div class="magnify" style="float: right; margin-left: 3px; margin-right: 0px;"><a href="https://en.wikipedia.org/wiki/File:RNA_polymerase_transcribing_template_strand_DNA.png" class="internal" title="Enlarge" style="color: rgb(11, 0, 128); background-image: linear-gradient(transparent, transparent), url(http://cafe.daum.net/w/resources/src/mediawiki.skinning/images/magnify-clip-ltr.svg?8330e); background-attachment: initial, initial; background-origin: initial, initial; background-clip: initial, initial; background-size: initial, initial; display: block; text-indent: 15px; white-space: nowrap; overflow: hidden; width: 15px; height: 11px; background-position: ; background-repeat: ;"></a></div>RNA polymerase transcribes the template strand of DNA to produce the complementary messenger RNA</div></div></div><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);"><b><span style="color: rgb(255, 0, 0);">Transcription occurs in the cell nucleus using DNA as a template to produce an RNA molecule</span></b>. In eukaryotes, this RNA molecule is known as pre-mRNA as it undergoes post-transcriptional processing to produce a mature mRNA molecule. However, in prokaryotes post-transcriptional processing is not required so the mature mRNA molecule is immediately produced.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">First, an enzyme known as a&nbsp;<a href="https://en.wikipedia.org/wiki/Helicase" title="Helicase" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">helicase</a>&nbsp;acts on the molecule of DNA. DNA has an&nbsp;<a href="https://en.wikipedia.org/wiki/Antiparallel_(biochemistry)" title="Antiparallel (biochemistry)" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">antiparallel</a>, double helix structure composed of two,&nbsp;<a href="https://en.wikipedia.org/w/index.php?title=Complementary_(molecular_biology)&amp;action=edit&amp;redlink=1" class="new" title="Complementary (molecular biology) (page does not exist)" style="color: rgb(165, 88, 88); background-image: none; background-position: initial initial; background-repeat: initial initial;">complementary</a>&nbsp;<a href="https://en.wikipedia.org/wiki/Polynucleotide" title="Polynucleotide" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">polynucleotide</a>&nbsp;strands, held together by&nbsp;<a href="https://en.wikipedia.org/wiki/Hydrogen_bond" title="Hydrogen bond" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">hydrogen bonds</a>&nbsp;between the base pairs. The helicase disrupts the hydrogen bonds causing a region of DNA - corresponding to a gene - to unwind, separating the two DNA strands and exposing a series of bases. Despite DNA being a double stranded molecule, only one of the strands acts as a template for pre-mRNA synthesis - this strand is known as the template strand. The other DNA strand (which is&nbsp;<a href="https://en.wikipedia.org/wiki/Complementarity_(molecular_biology)" title="Complementarity (molecular biology)" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">complementary</a>&nbsp;to the template strand) is known as the coding strand.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">The enzyme&nbsp;<a href="https://en.wikipedia.org/wiki/RNA_polymerase" title="RNA polymerase" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">RNA polymerase</a>&nbsp;then binds to the exposed template strand and reads from the&nbsp;<a href="https://en.wikipedia.org/w/index.php?title=Directionality_(molecular_biology&amp;action=edit&amp;redlink=1" class="new" title="Directionality (molecular biology (page does not exist)" style="color: rgb(165, 88, 88); background-image: none; background-position: initial initial; background-repeat: initial initial;">3-prime</a>&nbsp;(3') end to the&nbsp;<a href="https://en.wikipedia.org/w/index.php?title=Directionality_(molecular_biology&amp;action=edit&amp;redlink=1" class="new" title="Directionality (molecular biology (page does not exist)" style="color: rgb(165, 88, 88); background-image: none; background-position: initial initial; background-repeat: initial initial;">5-prime</a>&nbsp;(5') end. Simultaneously, the RNA polymerase synthesises a single strand of pre-mRNA (in the 5'-to-3' direction) through complementary&nbsp;<a href="https://en.wikipedia.org/wiki/Base_pair" title="Base pair" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">base pairing</a>&nbsp;with the exposed nucleotides on the template strand. The pre-mRNA molecule is built by the addition of single nucleotides by RNA polymerase as it moves along the DNA template strand, behind the RNA polymerase the two strands of DNA rejoin so only 12 base pairs on the DNA are exposed at a time&nbsp;<sup id="cite_ref-Toole2015_5-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Toole2015-5" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[5]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">The pre-mRNA molecule synthesised is complementary in sequence to the template DNA strand and shares the same nucleotide sequence as the coding DNA strand. However, there is one crucial difference in the nucleotide composition of DNA and RNA molecules. DNA is composed of 4 bases -&nbsp;<a href="https://en.wikipedia.org/wiki/Guanine" title="Guanine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">guanine</a>,&nbsp;<a href="https://en.wikipedia.org/wiki/Cytosine" title="Cytosine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">cytosine</a>,&nbsp;<a href="https://en.wikipedia.org/wiki/Adenine" title="Adenine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">adenine</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/Thymine" title="Thymine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">thymine</a>&nbsp;(G, C, A and T) - RNA is also composed of 4 bases - guanine, cytosine, adenine and&nbsp;<a href="https://en.wikipedia.org/wiki/Uracil" title="Uracil" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">uracil</a>. In RNA molecules, the DNA base thymine is replaced by uracil, therefore, in the pre-mRNA molecule, all complementary bases which would be thymines are replaced by uracil&nbsp;<sup id="cite_ref-Berk2000_6-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Berk2000-6" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[6]</a></sup>. When RNA polymerases reaches a specific DNA sequence which&nbsp;<a href="https://en.wikipedia.org/wiki/Stop_codon" title="Stop codon" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">terminates</a>&nbsp;transcription, RNA polymerase detaches and pre-mRNA synthesis is complete.</p><h3 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); margin: 0.3em 0px 0px; overflow: hidden; padding-top: 0.5em; padding-bottom: 0px; border-bottom-width: 0px; font-size: 1.2em; line-height: 1.6; font-family: sans-serif; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Post-transcriptional_modification">Post-transcriptional modification</span><span class="mw-editsection" style="font-size:10pt; font-weight: normal; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=2" title="Edit section: Post-transcriptional modification" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h3><div class="thumb tright" style="margin: 0.5em 0px 1.3em 1.4em; width: auto; background-color: rgb(255, 255, 255); clear: right; float: right; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2;"><div class="thumbinner" style="min-width: 100px; border: 1px solid rgb(200, 204, 209); padding: 3px; background-color: rgb(248, 249, 250); font-size: 13.16px; text-align: center; overflow: hidden; width: 302px;"><a href="https://en.wikipedia.org/wiki/File:Messenger_RNA_maturation.png" class="image" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><img alt="" src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2Fthumb%2F9%2F91%2FMessenger_RNA_maturation.png%2F300px-Messenger_RNA_maturation.png" decoding="async" width="300" height="212" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/9/91/Messenger_RNA_maturation.png/450px-Messenger_RNA_maturation.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/9/91/Messenger_RNA_maturation.png/600px-Messenger_RNA_maturation.png 2x" data-file-width="1018" data-file-height="720" style="border: 1px solid rgb(200, 204, 209); vertical-align: middle; background-color: rgb(255, 255, 255);"></a><div class="thumbcaption" style="border: 0px; line-height: 1.4em; padding: 3px; font-size: 12.3704px; text-align: left;"><div class="magnify" style="float: right; margin-left: 3px; margin-right: 0px;"><a href="https://en.wikipedia.org/wiki/File:Messenger_RNA_maturation.png" class="internal" title="Enlarge" style="color: rgb(11, 0, 128); background-image: linear-gradient(transparent, transparent), url(http://cafe.daum.net/w/resources/src/mediawiki.skinning/images/magnify-clip-ltr.svg?8330e); background-attachment: initial, initial; background-origin: initial, initial; background-clip: initial, initial; background-size: initial, initial; display: block; text-indent: 15px; white-space: nowrap; overflow: hidden; width: 15px; height: 11px; background-position: ; background-repeat: ;"></a></div>Maturation of pre-spliced mRNA through polyadenylation and addition of the 5' cap before undergoing splicing</div></div></div><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Once transcription is complete, the pre-mRNA molecule undergoes&nbsp;<a href="https://en.wikipedia.org/wiki/Post-transcriptional_modification" title="Post-transcriptional modification" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">post-transcriptional processing</a>&nbsp;to produce a mature, functional mRNA molecule.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">T<b>here are 3 key steps within post-transcriptional processing</b>:</p><ol style="margin: 0.3em 0px 0px 3.2em; padding: 0px; list-style-image: none; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);"><li style="margin-bottom: 0.1em;">Addition of a&nbsp;<a href="https://en.wikipedia.org/wiki/Five-prime_cap" title="Five-prime cap" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">5' cap</a>&nbsp;to the start of the pre-MRNA molecule</li><li style="margin-bottom: 0.1em;">Addition of a 3'&nbsp;<a href="https://en.wikipedia.org/wiki/Polyadenylation" title="Polyadenylation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">poly(A) tail</a>&nbsp;is added to the end pre-mRNA molecule</li><li style="margin-bottom: 0.1em;">Removal of&nbsp;<a href="https://en.wikipedia.org/wiki/Intron" title="Intron" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">introns</a>&nbsp;from the pre-mRNA molecule via&nbsp;<a href="https://en.wikipedia.org/wiki/RNA_splicing" title="RNA splicing" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">RNA splicing</a></li></ol><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">The 5' cap is added to the 5' end (start) of the pre-mRNA molecule and is composed of a modified guanine nucleotide. The purpose of the 5' cap is to prevent the pre-mRNA and mature mRNA molecules from being broken down in the cell before they are translated, the cap also aids binding of the ribosome to the mRNA to start translation. In contrast, the 3' Poly(A) tail is added to the 3' end of the mRNA molecule. The Poly(A) tail is composed of a 100-200 adenine bases added by enzymes to the end of the pre-mRNA molecule&nbsp;<sup id="cite_ref-Khan2020_7-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Khan2020-7" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[7]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">This processed pre-mRNA molecule then undergoes the process of splicing. During splicing, nucleotide sequences known as introns are removed from the pre-mRNA molecule by a multi-protein complex known as a&nbsp;<a href="https://en.wikipedia.org/wiki/Spliceosome" title="Spliceosome" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">spliceosome</a>&nbsp;(composed of over 150 proteins and RNA)&nbsp;<sup id="cite_ref-Jo2015_8-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Jo2015-8" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[8]</a></sup>&nbsp;to produce the final, mature mRNA molecule. Genes are composed of a series of introns and&nbsp;<a href="https://en.wikipedia.org/wiki/Exon" title="Exon" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">exons</a>, introns are nucleotide sequences within the gene that do not encode the protein while, exons are nucleotide sequences which directly encode a protein. Introns and exons are present in both the underlying DNA sequence and the pre-mRNA molecule but are removed by splicing to produce the final mRNA molecule. This mature mRNA molecule is then exported from the nucleus into the cytoplasm through nuclear pores in the envelope of the nucleus.</p><h2 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); font-weight: normal; margin: 1em 0px 0.25em; overflow: hidden; padding: 0px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(162, 169, 177); font-family: 'Linux Libertine', Georgia, Times, serif; line-height: 1.3; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Translation">Translation</span><span class="mw-editsection" style="font-family: sans-serif; font-size:10pt; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=3" title="Edit section: Translation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h2><div role="note" class="hatnote navigation-not-searchable" style="font-style: italic; padding-left: 1.6em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Main article:&nbsp;<a href="https://en.wikipedia.org/wiki/Translation_(biology)" title="Translation (biology)" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">Translation (biology)</a></div><div class="thumb tright" style="margin: 0.5em 0px 1.3em 1.4em; width: auto; background-color: rgb(255, 255, 255); clear: right; float: right; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2;"><div class="thumbinner" style="min-width: 100px; border: 1px solid rgb(200, 204, 209); padding: 3px; background-color: rgb(248, 249, 250); font-size: 13.16px; text-align: center; overflow: hidden; width: 502px;"><a href="https://en.wikipedia.org/wiki/File:Translation_-_cycle.png" class="image" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><img alt="" src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2Fthumb%2F4%2F49%2FTranslation_-_cycle.png%2F500px-Translation_-_cycle.png" decoding="async" width="500" height="213" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/4/49/Translation_-_cycle.png/750px-Translation_-_cycle.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/4/49/Translation_-_cycle.png/1000px-Translation_-_cycle.png 2x" data-file-width="1430" data-file-height="608" style="border: 1px solid rgb(200, 204, 209); vertical-align: middle; background-color: rgb(255, 255, 255);"></a><div class="thumbcaption" style="border: 0px; line-height: 1.4em; padding: 3px; font-size: 12.3704px; text-align: left;"><div class="magnify" style="float: right; margin-left: 3px; margin-right: 0px;"><a href="https://en.wikipedia.org/wiki/File:Translation_-_cycle.png" class="internal" title="Enlarge" style="color: rgb(11, 0, 128); background-image: linear-gradient(transparent, transparent), url(http://cafe.daum.net/w/resources/src/mediawiki.skinning/images/magnify-clip-ltr.svg?8330e); background-attachment: initial, initial; background-origin: initial, initial; background-clip: initial, initial; background-size: initial, initial; display: block; text-indent: 15px; white-space: nowrap; overflow: hidden; width: 15px; height: 11px; background-position: ; background-repeat: ;"></a></div>Translation process showing the cycle of tRNA addition and amino acid incorporation into the growing polypeptide chain</div></div></div><div class="thumb tright" style="margin: 0.5em 0px 1.3em 1.4em; width: auto; background-color: rgb(255, 255, 255); clear: right; float: right; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2;"><div class="thumbinner" style="min-width: 100px; border: 1px solid rgb(200, 204, 209); padding: 3px; background-color: rgb(248, 249, 250); font-size: 13.16px; text-align: center; overflow: hidden; width: 252px;"><a href="https://en.wikipedia.org/wiki/File:Protein_translation.gif" class="image" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><img alt="" src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2F9%2F94%2FProtein_translation.gif" decoding="async" width="250" height="250" class="thumbimage" data-file-width="250" data-file-height="250" style="border: 1px solid rgb(200, 204, 209); vertical-align: middle; background-color: rgb(255, 255, 255);"></a><div class="thumbcaption" style="border: 0px; line-height: 1.4em; padding: 3px; font-size: 12.3704px; text-align: left;"><div class="magnify" style="float: right; margin-left: 3px; margin-right: 0px;"><a href="https://en.wikipedia.org/wiki/File:Protein_translation.gif" class="internal" title="Enlarge" style="color: rgb(11, 0, 128); background-image: linear-gradient(transparent, transparent), url(http://cafe.daum.net/w/resources/src/mediawiki.skinning/images/magnify-clip-ltr.svg?8330e); background-attachment: initial, initial; background-origin: initial, initial; background-clip: initial, initial; background-size: initial, initial; display: block; text-indent: 15px; white-space: nowrap; overflow: hidden; width: 15px; height: 11px; background-position: ; background-repeat: ;"></a></div>A&nbsp;<a href="https://en.wikipedia.org/wiki/Ribosome" title="Ribosome" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">ribosome</a>&nbsp;is a&nbsp;<a href="https://en.wikipedia.org/wiki/Biological_machine" class="mw-redirect" title="Biological machine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">biological machine</a>&nbsp;that utilizes&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_dynamics" title="Protein dynamics" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">protein dynamics</a>&nbsp;on&nbsp;<a href="https://en.wikipedia.org/wiki/Nanoscale" class="mw-redirect" title="Nanoscale" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">nanoscales</a></div></div></div><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);"><b><span style="color: rgb(255, 0, 0);">Translation is the process of synthesising an amino acid polypeptide chain from the mRNA template molecule</span></b>. In eukaryotes, translation occurs in the cytoplasm, where the ribosomes are located either free floating or attached to the&nbsp;<a href="https://en.wikipedia.org/wiki/Endoplasmic_reticulum" title="Endoplasmic reticulum" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">endoplasmic reticulum</a>. In prokaryotes, which lack a nucleus, the processes of transcription and translation both occur in the cytoplasm&nbsp;<sup id="cite_ref-Khan_Academy_2020_9-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Khan_Academy_2020-9" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[9]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);"><b><a href="https://en.wikipedia.org/wiki/Ribosome" title="Ribosome" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span style="color: rgb(255, 0, 0);">Ribosomes</span></a><span style="color: rgb(255, 0, 0);">&nbsp;are complex&nbsp;</span><a href="https://en.wikipedia.org/wiki/Molecular_machine" title="Molecular machine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><span style="color: rgb(255, 0, 0);">molecular machines</span></a><span style="color: rgb(255, 0, 0);">, made of a mixture of protein and RNA, arranged into two subunit (a large and small subunit), which surround the mRNA molecule. The ribosome reads the mRNA molecule in a 5'-3' direction and uses the mRNA as a template to determine the order of amino acids in the polypeptide chain</span></b>&nbsp;<sup id="cite_ref-Khan_Academy_2020_-_2_10-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Khan_Academy_2020_-_2-10" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[10]</a></sup>. In order to translate the mRNA molecule, the ribosome uses small molecules known as&nbsp;<a href="https://en.wikipedia.org/wiki/Transfer_RNA" title="Transfer RNA" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">transfer RNAs</a>&nbsp;(tRNA) to bring the correct amino acids to the ribosome. Each tRNA is composed of 70-80 nucleotides and adopts a characteristic cloverleaf structure due to the formation of hydrogen bonds between nucleotides within the molecule.&nbsp;<sup id="cite_ref-Cooper_2000_11-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Cooper_2000-11" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[11]</a></sup>&nbsp;There are around 60 different types of tRNAs, which serve as adaptors in this process, each binds to a specific nucleotide sequence (known as a&nbsp;<a href="https://en.wikipedia.org/wiki/Codon" class="mw-redirect" title="Codon" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">codon</a>) in the mRNA molecule and delivering a specific amino acid.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">The ribosome initially attaches to the mRNA at the&nbsp;<a href="https://en.wikipedia.org/wiki/Start_codon" title="Start codon" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">start codon</a>&nbsp;(AUG) and begins to translate the mRNA molecule using codon-anticodon base pairing. The mRNA nucleotide sequence is read in&nbsp;<a href="https://en.wikipedia.org/wiki/Genetic_code" title="Genetic code" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">triplets</a>&nbsp;- three adjacent nucleotides in the mRNA molecule correspond to a single codon. Each tRNA has an exposed sequence of three nucleotides, known as the anticodon, which are complementary in sequence to the codon on the mRNA molecule. For example, the first codon encountered on the mRNA molecule is the start codon, composed of the nucleotides AUG, the correct tRNA with the anticodon (complementary 3 nucleotide sequence UAC) binds to the mRNA using the ribosome. This tRNA delivers the correct amino acid corresponding to the mRNA codon, in the case of the start codon, the correct amino acid is methionine. The next codon (adjacent to the start codon) is then bound by the correct tRNA with complementary anticodon, delivering the next amino acid to ribosome. The ribosome then uses its enzymatic activity&nbsp;<a href="https://en.wikipedia.org/wiki/Peptidyl_transferase" title="Peptidyl transferase" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">peptidyl transferase</a>&nbsp;to catalyse the formation of the covalent peptide bond between the two adjacent amino acids&nbsp;<sup id="cite_ref-Toole2015_5-1" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Toole2015-5" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[5]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">The ribosome then moves along the mRNA molecule to the third codon, releasing the first tRNA molecule, as only two tRNA molecules can be brought together by a single ribosome at one time. The next complementary tRNA with the correct anticodon complementary to the third codon is selected for, delivering the next amino acid to the ribosome which is covalently joined to the growing polypeptide chain. This process continues with the ribosome moving along the mRNA molecule adding up to 15 amino acids per second to the polypeptide chain. Behind the first ribosome, up to 50 additional ribosomes can bind to the mRNA molecule and synthesise an identical polypeptide - this enables simultaneous synthesis of multiple identical polypeptide chains&nbsp;<sup id="cite_ref-Toole2015_5-2" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Toole2015-5" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[5]</a></sup>. Termination of the growing polypeptide chain occurs when the ribosome encounters a stop codon (UAA, UAG, or UGA) in the mRNA molecule. When this happens, no tRNA can recognise it and a&nbsp;<a href="https://en.wikipedia.org/wiki/Release_factor" title="Release factor" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">release factor</a>&nbsp;induces the release of the polypeptide chain from the ribosome&nbsp;<sup id="cite_ref-Cooper_2000_11-1" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Cooper_2000-11" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[11]</a></sup>.</p><h2 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); font-weight: normal; margin: 1em 0px 0.25em; overflow: hidden; padding: 0px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(162, 169, 177); font-family: 'Linux Libertine', Georgia, Times, serif; line-height: 1.3; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Protein_Folding">Protein Folding</span><span class="mw-editsection" style="font-family: sans-serif; font-size:10pt; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=4" title="Edit section: Protein Folding" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h2><div class="thumb tright" style="margin: 0.5em 0px 1.3em 1.4em; width: auto; background-color: rgb(255, 255, 255); clear: right; float: right; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2;"><div class="thumbinner" style="min-width: 100px; border: 1px solid rgb(200, 204, 209); padding: 3px; background-color: rgb(248, 249, 250); font-size: 13.16px; text-align: center; overflow: hidden; width: 302px;"><a href="https://en.wikipedia.org/wiki/File:Protein_folding_figure.png" class="image" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><img alt="" src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2Fthumb%2Fd%2Fdd%2FProtein_folding_figure.png%2F300px-Protein_folding_figure.png" decoding="async" width="300" height="355" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Protein_folding_figure.png/450px-Protein_folding_figure.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Protein_folding_figure.png/600px-Protein_folding_figure.png 2x" data-file-width="1042" data-file-height="1232" style="border: 1px solid rgb(200, 204, 209); vertical-align: middle; background-color: rgb(255, 255, 255);"></a><div class="thumbcaption" style="border: 0px; line-height: 1.4em; padding: 3px; font-size: 12.3704px; text-align: left;"><div class="magnify" style="float: right; margin-left: 3px; margin-right: 0px;"><a href="https://en.wikipedia.org/wiki/File:Protein_folding_figure.png" class="internal" title="Enlarge" style="color: rgb(11, 0, 128); background-image: linear-gradient(transparent, transparent), url(http://cafe.daum.net/w/resources/src/mediawiki.skinning/images/magnify-clip-ltr.svg?8330e); background-attachment: initial, initial; background-origin: initial, initial; background-clip: initial, initial; background-size: initial, initial; display: block; text-indent: 15px; white-space: nowrap; overflow: hidden; width: 15px; height: 11px; background-position: ; background-repeat: ;"></a></div>Shows the process of protein folding from primary structure through to quaternary structure</div></div></div><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);"><b><span style="color: rgb(255, 0, 0);">Once synthesis of the polypeptide chain is completed by the ribosome, the polypeptide chain released and folds to adopt a specific structure which enables the protein to carry out its functions</span></b>. The basic form of&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_structure" title="Protein structure" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">protein structure</a>&nbsp;is known as the&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_primary_structure" title="Protein primary structure" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">primary structure</a>, which is simply the polypeptide chain i.e. a sequence of covalently bonded amino acids. The primary structure of a protein is encoded by a gene. Therefore, any changes to the sequence of the gene can alter the primary structure of the protein and all subsequent levels of protein structure ultimately changing the overall structure and function.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">The primary structure of a protein (the polypeptide chain) can then fold or coil to form the&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_secondary_structure" title="Protein secondary structure" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">secondary structure</a>&nbsp;of the protein. The most common types of secondary structure are known as an&nbsp;<a href="https://en.wikipedia.org/wiki/Alpha_helix" title="Alpha helix" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">alpha helix</a>&nbsp;or&nbsp;<a href="https://en.wikipedia.org/wiki/Beta_sheet" title="Beta sheet" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">beta sheet</a>, these are small structures produced by hydrogen bonds forming within the polypeptide chain. This secondary structure then folds to produce the&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_tertiary_structure" title="Protein tertiary structure" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">tertiary structure</a>&nbsp;of the protein, this is its overall 3D structure which is made of different secondary structures folding together. In the tertiary structure, key protein features e.g. the active site, are folded and formed enabling the protein to function. Finally, whilst most proteins are made of a single polypeptide chain, however, some proteins are composed of multiple polypeptide chains (known as subunits) which fold and interact to form the&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_quaternary_structure" title="Protein quaternary structure" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">quaternary structure</a>. Hence, this is a&nbsp;<a href="https://en.wikipedia.org/w/index.php?title=Multi-subunit_complex&amp;action=edit&amp;redlink=1" class="new" title="Multi-subunit complex (page does not exist)" style="color: rgb(165, 88, 88); background-image: none; background-position: initial initial; background-repeat: initial initial;">multi-subunit complex</a>&nbsp;composed of multiple folded, polypeptide chain subunits&nbsp;<sup id="cite_ref-Khan_proteins_2020_12-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Khan_proteins_2020-12" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[12]</a></sup>.</p><h3 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); margin: 0.3em 0px 0px; overflow: hidden; padding-top: 0.5em; padding-bottom: 0px; border-bottom-width: 0px; font-size: 1.2em; line-height: 1.6; font-family: sans-serif; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Role_of_Protein_Synthesis_in_Disease">Role of Protein Synthesis in Disease</span><span class="mw-editsection" style="font-size:10pt; font-weight: normal; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=5" title="Edit section: Role of Protein Synthesis in Disease" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h3><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Many diseases are caused by mutations in genes, due to the direct connection between the genetic code of the gene and the amino acid sequence of the encoded protein. Changes to the primary structure of the protein can result in the protein mis-folding and unable to function. Mutations within a single gene have been identified as a cause of multiple diseases, including&nbsp;<a href="https://en.wikipedia.org/wiki/Sickle_cell_disease" title="Sickle cell disease" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">sickle cell disease</a>, known as single gene disorders.</p><div class="thumb tright" style="margin: 0.5em 0px 1.3em 1.4em; width: auto; background-color: rgb(255, 255, 255); clear: right; float: right; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2;"><div class="thumbinner" style="min-width: 100px; border: 1px solid rgb(200, 204, 209); padding: 3px; background-color: rgb(248, 249, 250); font-size: 13.16px; text-align: center; overflow: hidden; width: 402px;"><a href="https://en.wikipedia.org/wiki/File:Sickle_Cell_Anaemia_red_blood_cells_in_blood_vessels.png" class="image" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><img alt="" src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2Fthumb%2Fa%2Fab%2FSickle_Cell_Anaemia_red_blood_cells_in_blood_vessels.png%2F400px-Sickle_Cell_Anaemia_red_blood_cells_in_blood_vessels.png" decoding="async" width="400" height="179" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/a/ab/Sickle_Cell_Anaemia_red_blood_cells_in_blood_vessels.png/600px-Sickle_Cell_Anaemia_red_blood_cells_in_blood_vessels.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/a/ab/Sickle_Cell_Anaemia_red_blood_cells_in_blood_vessels.png/800px-Sickle_Cell_Anaemia_red_blood_cells_in_blood_vessels.png 2x" data-file-width="1370" data-file-height="614" style="border: 1px solid rgb(200, 204, 209); vertical-align: middle; background-color: rgb(255, 255, 255);"></a><div class="thumbcaption" style="border: 0px; line-height: 1.4em; padding: 3px; font-size: 12.3704px; text-align: left;"><div class="magnify" style="float: right; margin-left: 3px; margin-right: 0px;"><a href="https://en.wikipedia.org/wiki/File:Sickle_Cell_Anaemia_red_blood_cells_in_blood_vessels.png" class="internal" title="Enlarge" style="color: rgb(11, 0, 128); background-image: linear-gradient(transparent, transparent), url(http://cafe.daum.net/w/resources/src/mediawiki.skinning/images/magnify-clip-ltr.svg?8330e); background-attachment: initial, initial; background-origin: initial, initial; background-clip: initial, initial; background-size: initial, initial; display: block; text-indent: 15px; white-space: nowrap; overflow: hidden; width: 15px; height: 11px; background-position: ; background-repeat: ;"></a></div>A comparison between a healthy individual and a sufferer of sickle cell anaemia showing the different red blood cell shapes and differing flow within blood vessels</div></div></div><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Sickle cell disease is a group of diseases caused by a mutation in a subunit of&nbsp;<a href="https://en.wikipedia.org/wiki/Haemoglobin" class="mw-redirect" title="Haemoglobin" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">haemoglobin</a>, a protein found in red blood cells responsible for transporting oxygen, the most dangerous of these diseases is known as sickle cell anaemia. Sickle cell anaemia is the most common&nbsp;<a href="https://en.wikipedia.org/wiki/Genetic_disorder" title="Genetic disorder" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">homozygous recessive single gene disorder</a>, meaning the individual must carry a mutation in both copies of the gene to suffer from the disease. Haemoglobin is composed of four subunits - two A subunits and two B subunits.&nbsp;<sup id="cite_ref-Steinberg_2016_13-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Steinberg_2016-13" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[13]</a></sup>. Patients suffering from sickle cell anaemia have a missense mutation in the haemoglobin B subunit gene. A missense mutation means the nucleotide mutation alters the overall codon triplet such that a different amino acid is paired with the new codon. In the case of sickle cell anaemia, the most common missense mutation is the single nucleotide mutation from thymine to adenine in the haemoglobin B subunit gene&nbsp;<sup id="cite_ref-StatPearls_2020_14-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-StatPearls_2020-14" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[14]</a></sup>&nbsp;which changes codon 6 from encoding glutamic acid to encoding valine&nbsp;<sup id="cite_ref-Steinberg_2016_13-1" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Steinberg_2016-13" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[13]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">This change in the primary structure of the haemoglobin B subunit alters the functionality of the haemoglobin multi-subunit complex in low oxygen conditions. When red blood cells unload oxygen into the tissues of the body, the mutated haemoglobin starts to stick together to form a semi-solid structure within the red blood cell. This distorts the shape of the red blood cell, resulting in the characteristic "sickle" red blood cell shape, and reduces flexibility. This rigid, distorted red blood cell can aggregate in blood vessels creating a blockage. The blockage prevents blood flow to the tissue and can lead to&nbsp;<a href="https://en.wikipedia.org/wiki/Tissue_death" class="mw-redirect" title="Tissue death" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">necrosis</a>&nbsp;which causes pain to the individual&nbsp;<sup id="cite_ref-Ilesanmi_2010_15-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Ilesanmi_2010-15" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[15]</a></sup>.</p><h2 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); font-weight: normal; margin: 1em 0px 0.25em; overflow: hidden; padding: 0px; border-bottom-width: 1px; border-bottom-style: solid; border-bottom-color: rgb(162, 169, 177); font-family: 'Linux Libertine', Georgia, Times, serif; line-height: 1.3; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Post-translational_modifications">Post-translational modifications</span><span class="mw-editsection" style="font-family: sans-serif; font-size:10pt; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=6" title="Edit section: Post-translational modifications" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h2><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Completion of protein folding into the mature, functional 3D state is not necessarily the end of the protein maturation pathway. A folded protein can still undergo further processing in the form of post-translation modifications. There are over 200 known types of post-translation modification which can occur, these modifications can alter protein activity, the ability of the protein to interact with other proteins and where the protein is found within the cell e.g. in the cell nucleus or cytoplasm&nbsp;<sup id="cite_ref-Duan_2015_16-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Duan_2015-16" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[16]</a></sup>. Through post-translational modification, the diversity of proteins encoded by the genome is expanded by 2 to 3&nbsp;<a href="https://en.wikipedia.org/wiki/Order_of_magnitude" title="Order of magnitude" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">orders of magnitude</a><sup id="cite_ref-Schubert_2015_17-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Schubert_2015-17" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[17]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">There are four key types of post-translational modification<sup id="cite_ref-18" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-18" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[18]</a></sup>:</p><ol style="margin: 0.3em 0px 0px 3.2em; padding: 0px; list-style-image: none; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);"><li style="margin-bottom: 0.1em;">Cleavage</li><li style="margin-bottom: 0.1em;">Addition of chemical groups</li><li style="margin-bottom: 0.1em;">Addition of complex molecules</li><li style="margin-bottom: 0.1em;">Formation of intramolecular bonds</li></ol><h3 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); margin: 0.3em 0px 0px; overflow: hidden; padding-top: 0.5em; padding-bottom: 0px; border-bottom-width: 0px; font-size: 1.2em; line-height: 1.6; font-family: sans-serif; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Cleavage">Cleavage</span><span class="mw-editsection" style="font-size:10pt; font-weight: normal; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=7" title="Edit section: Cleavage" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h3><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);"><a href="https://en.wikipedia.org/wiki/Proteolysis" title="Proteolysis" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">Cleavage</a>&nbsp;of proteins is an irreversible post-translational modification carried out by enzymes known as&nbsp;<a href="https://en.wikipedia.org/wiki/Proteases" class="mw-redirect" title="Proteases" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">proteases</a>. These proteases are often highly specific and cause&nbsp;<a href="https://en.wikipedia.org/wiki/Hydrolysis" title="Hydrolysis" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">hydrolysis</a>&nbsp;of a limited number of peptide bonds within the target protein. The resulting shortened protein has new beginning and end of the amino acid chain. This post-translational modification often alters the proteins function, a cleaved protein can be rendered inactive or newly activated and can display new biological activities&nbsp;<sup id="cite_ref-Ciechanover_2005_19-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Ciechanover_2005-19" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[19]</a></sup>.</p><h3 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); margin: 0.3em 0px 0px; overflow: hidden; padding-top: 0.5em; padding-bottom: 0px; border-bottom-width: 0px; font-size: 1.2em; line-height: 1.6; font-family: sans-serif; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Addition_of_chemical_groups">Addition of chemical groups</span><span class="mw-editsection" style="font-size:10pt; font-weight: normal; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=8" title="Edit section: Addition of chemical groups" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h3><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Following translation, small low molecular weight molecules can be added onto amino acids within the mature protein structure&nbsp;<sup id="cite_ref-Brenner_2001_20-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Brenner_2001-20" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[20]</a></sup>. Examples of processes which add chemical groups to the target protein include&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_methylation" title="Protein methylation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">methylation</a>,&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_acetylation" class="mw-redirect" title="Protein acetylation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">acetylation</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_phosphorylation" title="Protein phosphorylation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">phosphorylation</a>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Methylation is the reversible addition of a&nbsp;<a href="https://en.wikipedia.org/wiki/Methyl_group" title="Methyl group" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">methyl group</a>&nbsp;onto an amino acid catalysed by an enzyme known as a&nbsp;<a href="https://en.wikipedia.org/wiki/Methyltransferase" title="Methyltransferase" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">methyltransferase</a>. Methylation occurs on at least 9 of the 20 common amino acids, however, it mainly occurs on the amino acids&nbsp;<a href="https://en.wikipedia.org/wiki/Lysine" title="Lysine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">lysine</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/Arginine" title="Arginine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">arginine</a>. One example of a protein which is commonly methylated is a&nbsp;<a href="https://en.wikipedia.org/wiki/Histone" title="Histone" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">histone</a>, DNA is wrapped around histones in the nucleus, a highly specific pattern of&nbsp;<a href="https://en.wikipedia.org/wiki/Histone_methylation" title="Histone methylation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">histone methylation</a>&nbsp;is used to control gene transcription in the nucleus&nbsp;<sup id="cite_ref-Murn_2017_21-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Murn_2017-21" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[21]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Histone-based regulation of gene transcription is also modified by acetylation. Acetylation is the reversible covalent addition of an&nbsp;<a href="https://en.wikipedia.org/wiki/Acetyl_group" title="Acetyl group" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">acetyl group</a>&nbsp;onto a lysine amino acid, from a donor molecule known as&nbsp;<a href="https://en.wikipedia.org/wiki/Acetyl-CoA" title="Acetyl-CoA" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">acetyl coenzyme A</a>, by the enzyme&nbsp;<a href="https://en.wikipedia.org/wiki/Acetyltransferase" title="Acetyltransferase" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">acetyltransferase</a><sup id="cite_ref-Drazic_2016_22-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Drazic_2016-22" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[22]</a></sup>. The nuclear proteins&nbsp;<a href="https://en.wikipedia.org/wiki/Histone_acetylation_and_deacetylation" title="Histone acetylation and deacetylation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">histones undergo acetylation</a>&nbsp;on their lysine residues by enzymes known as&nbsp;<a href="https://en.wikipedia.org/wiki/Histone_acetyltransferase" title="Histone acetyltransferase" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">histone acetyltransferase</a>. The effect of acetylation is to weaken the interactions between the histone and DNA which makes more genes accessible for transcription&nbsp;<sup id="cite_ref-Bannister_2011_23-0" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Bannister_2011-23" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[23]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">The final, preval&#8206;ent post-translational chemical group modification is phosphorylation. Phosphorylation is the reversible, covalent addition of a&nbsp;<a href="https://en.wikipedia.org/wiki/Phosphate" title="Phosphate" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">phosphate</a>&nbsp;group to specific amino acids within the protein, mainly&nbsp;<a href="https://en.wikipedia.org/wiki/Serine" title="Serine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">serine</a>,&nbsp;<a href="https://en.wikipedia.org/wiki/Threonine" title="Threonine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">threonine</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/Tyrosine" title="Tyrosine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">tyrosine</a>, by a protein&nbsp;<a href="https://en.wikipedia.org/wiki/Kinase" title="Kinase" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">kinase</a>. Phosphorylation can drive proteins to interact with other proteins to produce a large, multi-protein complex&nbsp;<sup id="cite_ref-Alberts_2015_1-1" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Alberts_2015-1" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[1]</a></sup>.</p><h3 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); margin: 0.3em 0px 0px; overflow: hidden; padding-top: 0.5em; padding-bottom: 0px; border-bottom-width: 0px; font-size: 1.2em; line-height: 1.6; font-family: sans-serif; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Addition_of_complex_molecules">Addition of complex molecules</span><span class="mw-editsection" style="font-size:10pt; font-weight: normal; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=9" title="Edit section: Addition of complex molecules" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h3><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Post-translational modification can incorporate more complex, larger molecules into the mature protein structure by covalently adding the molecule onto amino acids within the polypeptide chain. One common example of this is&nbsp;<a href="https://en.wikipedia.org/wiki/Glycosylation" title="Glycosylation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">glycosylation</a>, which is widely considered to be most common post-translational modification&nbsp;<sup id="cite_ref-Schubert_2015_17-1" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Schubert_2015-17" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[17]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">In glycosylation, a polysaccharide molecule (known as a&nbsp;<a href="https://en.wikipedia.org/wiki/Glycan" title="Glycan" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">glycan</a>) is covalently added to a protein by enzymes known as&nbsp;<a href="https://en.wikipedia.org/wiki/Glycosyltransferases" class="mw-redirect" title="Glycosyltransferases" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">glycosyltransferases</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/Glycoside_hydrolases" class="mw-redirect" title="Glycoside hydrolases" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">glycosidases</a>&nbsp;in the cytoplasmic organelles the&nbsp;<a href="https://en.wikipedia.org/wiki/Endoplasmic_reticulum" title="Endoplasmic reticulum" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">endoplasmic reticulum</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/Golgi_apparatus" title="Golgi apparatus" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">Golgi apparatus</a>. Glycosylation can have a critical role in determining the final, folded 3D structure of target protein - in some cases glycosylation of the protein is necessary for correct folding. N-linked glycosylation promotes protein folding by increasing&nbsp;<a href="https://en.wikipedia.org/wiki/Solubility" title="Solubility" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">solubility</a>&nbsp;and mediates the protein binding to&nbsp;<a href="https://en.wikipedia.org/wiki/Chaperone_(protein)" title="Chaperone (protein)" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">chaperones</a><sup id="cite_ref-Alberts_2015_1-2" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Alberts_2015-1" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[1]</a></sup>.</p><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">There are broadly two types of glycosylation,&nbsp;<a href="https://en.wikipedia.org/wiki/N-linked_glycosylation" title="N-linked glycosylation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">N-linked glycosylation</a>&nbsp;and&nbsp;<a href="https://en.wikipedia.org/wiki/O-linked_glycosylation" title="O-linked glycosylation" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">O-linked glycosylation</a>. N-linked glycosylation starts in the endoplasmic reticulum with the addition of a precursor glycan. The precursor glycan is modified in the Golgi apparatus to produce complex glycan bound covalently bound to the nitrogen atom on an&nbsp;<a href="https://en.wikipedia.org/wiki/Asparagine" title="Asparagine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">asparagine</a>&nbsp;amino acid within the polypeptide chain. In contrast, O-linked glycosylation is the covalent sequential addition of individual sugars onto the oxygen atom in the amino acids serine and threonine within the mature protein structure&nbsp;<sup id="cite_ref-Alberts_2015_1-3" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Alberts_2015-1" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[1]</a></sup>.</p><h3 style="color: rgb(0, 0, 0); background-image: none; background-color: rgb(255, 255, 255); margin: 0.3em 0px 0px; overflow: hidden; padding-top: 0.5em; padding-bottom: 0px; border-bottom-width: 0px; font-size: 1.2em; line-height: 1.6; font-family: sans-serif; orphans: 2; text-align: start; widows: 2; background-position: initial initial; background-repeat: initial initial;"><span class="mw-headline" id="Formation_of_covalent_bonds">Formation of covalent bonds</span><span class="mw-editsection" style="font-size:10pt; font-weight: normal; margin-left: 1em; vertical-align: baseline; line-height: 1em; white-space: nowrap;"><span class="mw-editsection-bracket" style="margin-right: 0.25em; color: rgb(84, 89, 93);">[</span><a href="https://en.wikipedia.org/w/index.php?title=Protein_biosynthesis&amp;action=edit&amp;section=10" title="Edit section: Formation of covalent bonds" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">edit</a><span class="mw-editsection-bracket" style="margin-left: 0.25em; color: rgb(84, 89, 93);">]</span></span></h3><div class="thumb tright" style="margin: 0.5em 0px 1.3em 1.4em; width: auto; background-color: rgb(255, 255, 255); clear: right; float: right; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2;"><div class="thumbinner" style="min-width: 100px; border: 1px solid rgb(200, 204, 209); padding: 3px; background-color: rgb(248, 249, 250); font-size: 13.16px; text-align: center; overflow: hidden; width: 302px;"><a href="https://en.wikipedia.org/wiki/File:Formation_of_disulphide_covalent_bonds.png" class="image" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;"><img alt="" src="https://img1.daumcdn.net/relay/cafe/original/?fname=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2Fthumb%2Ff%2Ff6%2FFormation_of_disulphide_covalent_bonds.png%2F300px-Formation_of_disulphide_covalent_bonds.png" decoding="async" width="300" height="214" class="thumbimage" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/f/f6/Formation_of_disulphide_covalent_bonds.png/450px-Formation_of_disulphide_covalent_bonds.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/f/f6/Formation_of_disulphide_covalent_bonds.png/600px-Formation_of_disulphide_covalent_bonds.png 2x" data-file-width="1416" data-file-height="1008" style="border: 1px solid rgb(200, 204, 209); vertical-align: middle; background-color: rgb(255, 255, 255);"></a><div class="thumbcaption" style="border: 0px; line-height: 1.4em; padding: 3px; font-size: 12.3704px; text-align: left;"><div class="magnify" style="float: right; margin-left: 3px; margin-right: 0px;"><a href="https://en.wikipedia.org/wiki/File:Formation_of_disulphide_covalent_bonds.png" class="internal" title="Enlarge" style="color: rgb(11, 0, 128); background-image: linear-gradient(transparent, transparent), url(http://cafe.daum.net/w/resources/src/mediawiki.skinning/images/magnify-clip-ltr.svg?8330e); background-attachment: initial, initial; background-origin: initial, initial; background-clip: initial, initial; background-size: initial, initial; display: block; text-indent: 15px; white-space: nowrap; overflow: hidden; width: 15px; height: 11px; background-position: ; background-repeat: ;"></a></div>Shows the formation of disulphide covalent bonds as a post-translational modification. Disulphide bonds can either form within a single polypeptide chain (left) or between polypeptide chains in a multi-subunit protein complex (right)</div></div></div><p style="margin-top: 0.5em; margin-bottom: 0.5em; color: rgb(34, 34, 34); font-family: sans-serif; font-size: 14px; orphans: 2; text-align: start; widows: 2; background-color: rgb(255, 255, 255);">Many proteins produced within the cell are secreted outside of the cell, therefore, these proteins function as&nbsp;<a href="https://en.wikipedia.org/wiki/Extracellular" title="Extracellular" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">extracellular</a>&nbsp;proteins. Extracellular proteins are exposed to a variety of conditions outside the cell. In order to stabilise the functional, 3D structure of the protein, covalent bonds are formed either within the protein or between the different polypeptide chains in a multi-subunit complex. The most preval&#8206;ent type of covalent bond is a&nbsp;<a href="https://en.wikipedia.org/wiki/Disulfide" title="Disulfide" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">disulfide bond</a>&nbsp;(also known as a disulfide bridge). A disulphide bond is formed between two&nbsp;<a href="https://en.wikipedia.org/wiki/Cysteine" title="Cysteine" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">cysteine</a>&nbsp;amino acids using their side chain chemical groups containing a sulphur atom, known as&nbsp;<a href="https://en.wikipedia.org/wiki/Thiol" title="Thiol" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">thiol</a>&nbsp;functional groups. Disulfide bonds act to stabilise the&nbsp;<a href="https://en.wikipedia.org/wiki/Protein_structure" title="Protein structure" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">pre-existing conformation</a>&nbsp;of protein. Disulfide bonds are formed in an&nbsp;<a href="https://en.wikipedia.org/wiki/Redox" title="Redox" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">oxidation reaction</a>&nbsp;between two thiol groups and therefore, need an oxidising environment to react. As a result, disulfide bonds are typically formed in the oxidising environment of the endoplasmic reticulum catalysed by enzymes called protein disulfide isomerases. Disulfide bonds are rarely formed in the cytoplasm as it is a reducing environment&nbsp;<sup id="cite_ref-Alberts_2015_1-4" class="reference" style="line-height: 1; white-space: nowrap; font-size: 11.2px;"><a href="https://en.wikipedia.org/wiki/Protein_biosynthesis#cite_note-Alberts_2015-1" style="color: rgb(11, 0, 128); background-image: none; background-position: initial initial; background-repeat: initial initial;">[1]</a></sup></p></div></div></div></article><p><br></p>
<!-- -->